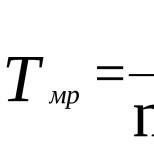Значимость коэффициента корреляции с помощью критерия стьюдента. Использование ПО при проведении корреляционного анализа. Пример применения метода корреляционного анализа
Полный вариант этой заметки (с формулами и таблицами) можно скачать с этой страницы в формате PDF. Размещенный на самой странице текст является кратким изложением содержания этой заметки и наиболее важных выводов.
Оптимистам от статистики посвящается
Коэффициент корреляции (КК) -- одна из наиболее простых и популярных статистик, характеризующих связь между случайными величинами. Одновременно КК удерживает первенство по числу сделанных с его помощью ошибочных и просто бессмысленных выводов. Такое положение обусловлено сложившейся практикой изложения материала, относящегося к корреляции и корреляционным зависимостям.
Большие, маленькие и "промежуточные" значения КК
При рассмотрении корреляционной связи подробно обсуждается понятие «сильной» (почти единичной) и «слабой» (почти нулевой) корреляции, но на практике ни та, ни другая никогда не встречаются. В результате остается неясным вопрос о разумной трактовке обычных для практики «промежуточных» значений КК. Коэффициент корреляции, равный 0.9 или 0.8 , новичку внушает оптимизм, а меньшие значения приводят его в замешательство.
По мере приобретения опыта оптимизм растет, и вот уже КК, равный 0.7 или 0.6 приводит исследователя в восторг, а оптимизм внушают значения 0.5 и 0.4 . Если же исследователь знаком с методами проверки статистических гипотез, то порог «хороших» значений КК падает до 0.3 или 0.2 .
Действительно, какие значения КК уже можно считать «достаточно большими», а какие остаются «слишком маленькими»? На этот вопрос имеется два диаметрально противоположных ответа -- оптимистичный и пессимистичный. Рассмотрим сначала оптимистичный (наиболее популярный) вариант ответа.
Значимость коэффициента корреляции
Этот вариант ответа дает нам классическая статистика и он связан с понятием статистической значимости КК. Мы рассмотрим здесь только ситуацию, когда интерес представляет положительная корреляционная связь (случай отрицательной корреляционной связи совершенно аналогичен). Более сложный случай, когда проверяется только наличие корреляционной связи без учета знака, относительно редко встречается на практике.
Если для КК r выполнено неравенство r > r e (n) , то говорят, что КК статистически значим при уровне значимости е . Здесь r e (n) -- квантиль, относительно которого нас будет интересовать только то, что при фиксированном уровне значимости e его значение стремится к нулю с ростом длины n выборки. Получается, что увеличивая массив данных можно добиться статистической значимости КК даже при весьма малых его значениях. В результате при наличии достаточно большой выборки появляется соблазн признать наличие в случае КК, равного, например, 0.06 . Тем не менее, здравый смысл подсказывает, что вывод о наличии значимой корреляционной связи при r=0.06 не может быть справедливым ни при каком объеме выборки. Остается понять природу ошибки. Для этого рассмотрим подробнее понятие статистической значимости.
Как обычно, при проверке статистических гипотез смысл проводимых расчетов кроется в выборе нуль-гипотезы и альтернативной гипотезы. При проверке значимости КК в качестве нуль-гипотезы берется предположение { r = 0 } при альтернативной гипотезе { r > 0 } (напомним, что мы рассматриваем здесь только ситуацию, когда интерес представляет положительная корреляционная связь). Выбираемый произвольно уровень значимости e определяет вероятность т.н. ошибки первого рода, когда нуль-гипотеза верна (r=0 ), но отклоняется статистическим критерием (т.е. критерий ошибочно признает наличие значимой корреляции). Выбирая уровень значимости, мы гарантируем малую вероятность такой ошибки, т.е. мы почти застрахованы от того, чтобы для независимых выборок (r=0 ) ошибочно признать наличие корреляционной связи (r > 0 ). Грубо говоря, значимость коэффициента корреляции означает только то, что он с большой вероятностью отличен от нуля .
Именно поэтому размер выборки и величина КК компенсируют друг друга -- большие выборки попросту позволяют добиться большей точности в локализации малого КК по его выборочной оценке.
Ясно, что понятие значимости не дает ответа на исходный вопрос о понимании категорий "большой/маленький" применительно к значениям КК. Ответ, даваемый критерием значимости, ничего не говорит нам о свойствах корреляционной связи, а позволяет только убедиться, что с большой вероятностью выполнено неравенство r > 0 . В то же время, само значение КК содержит значительно более существенную информацию о свойствах корреляционной связи. Действительно, одинаково значимые КК, равные 0.1 и 0.9 , существенно различаются по степени выраженности соответствующей корреляционной связи, а утверждение о значимости КК r = 0.06 для практики абсолютно бесполезно, поскольку при любых объемах выборки ни о какой корреляционной связи здесь говорить не приходится.
Окончательно можно сказать, что на практике из значимости коэффициента корреляции не следуют какие бы то ни было свойства корреляционной связи и даже само ее существование . С точки зрения практики порочен сам выбор альтернативной гипотезы, используемой при проверке значимости КК, поскольку случаи r=0 и r>0 при малых r с практической точки зрения неотличимы.
Фактически, когда из значимости КК выводят существование значимой корреляционной связи , производят совершенно беспардонную подмену понятий, основанную на смысловой неоднозначности слова "значимость". Значимость КК (четко определенное понятие) обманно превращают в "значимую корреляционную связь", а это словосочетание, не имеющее строгого определения, трактуют как синоним "выраженной корреляционной связи".
Расщепление дисперсии
Рассмотрим другой вариант ответа на вопрос о "малых" и "больших" значениях КК. Этот вариант ответа связан с выяснением регрессионоого смысла КК и оказывается весьма полезным для практики, хотя и отличается гораздо меньшим оптимизмом, чем критерии значимости КК.
Интересно, что обсуждение регрессионоого смысла КК часто наталкивается на трудности дидактического (а скорее психологического) характера. Кратко прокомментируем их. После формального введения КК и пояснения смысла "сильной" и "слабой" корреляционной связи считается необходимым углубиться в обсуждение философских вопросов соотношения между корреляционными и причинно-следственными связями. При этом делаются энергичные попытки откреститься от (гипотетической!) попытки трактовать корреляционную связь как причинно-следственную. На этом фоне обсуждение вопроса о наличии функциональной зависимости (в том числе и регрессионной) между коррелирующими величинами начинает казаться попросту кощунственной. Ведь от функциональной зависимости до причинно-следственной связи всего один шаг! В результате вопрос о регрессионном смысле КК вообще обходится стороной, так же как и вопрос о корреляционных свойствах линейной регресии.
На самом деле тут все просто. Если для нормированных (т.е. имеющих нулевое матожидание и единичную дисперсию) случайных величин X и Y имеет место соотношение
Y = a + bX + N,
где N -- некоторая случайная величина с нулевым матожиданием (аддитивный шум), то легко убедиться, что a = 0 и b = r . Это соотношение между случайными величинами X и Y называется уравнением линейной регрессии.
Вычисляя дисперсию случайной величины Y легко получить следующее выражение:
D[Y] = b 2 D[X] + D[N].
В последнем выражении первое слагаемое определяет вклад случайной величины X в дисперсию Y , а второе слагаемое -- вклад шума N в дисперсию Y . Используя полученное выше выражение для параметра b , легко выразить вклады случайных величин X и N через величину r = r (напомним, что мы считаем величины X и Y нормированными, т.е. D[X] = D[Y] = 1 ):
b 2 D[X] = r 2
D[N] = 1 - r 2
С учетом полученных формул часто говорят, что для случайных величин X и Y , связанных регрессионным уравнением, величина r 2 определяет долю дисперсии случайной величины Y , линейно обусловленную изменением случайной величины X . Итак, суммарная дисперсия случайной величины Y распадается на дисперсию, линейно обусловленную наличием регрессионной связи и остаточную дисперсию , обусловленную присутствием аддитивного шума.
Рассмотрим диаграмму рассеяния двумерной случайной величины (X, Y) . При малых D[N] диаграмма рассеяния вырождается в линейную зависимость между случайными величинами, слегка искаженную аддитивным шумом (т.е. точки на диаграмме рассеяния будут в основном сосредоточены вблизи прямой X=Y ). Такой случай имеет место при значениях r , близких по модулю к единице. При уменьшении (по модулю) величины КК дисперсия шумовой составляющей N начинает давать все больший вклад в дисперсию величины Y и при малых r диаграмма рассеяния полностью теряет сходство с прямой линией. В этом случае мы имеем облако точек, рассеяние которых в основном обусловлено шумом. Именно этот случай реализуется при значимых, но малых по абсолютной величине значениях КК. Ясно, что в этом случае ни о какой корреляционной связи говорить не приходится.
Посмотрим теперь, какой вариант ответа на вопрос о "больших" и "маленьких" значениях КК предлагает нам регрессионная интерпретация КК. В первую очередь необходимо подчеркнуть, что именно дисперсия является наиболее естественной мерой рассеяния значений случайной величины. Природа этой "естественности" состоит в аддитивности дисперсии для независимых случайных величин, но это свойство имеет очень многообразные проявления, к числу которых относится и продемонстрированное выше расщепление дисперсии на линейно обусловленную и остаточную дисперсии.
Итак, величина r 2 определяет долю дисперсии величины Y , линейно обусловленную наличием регрессионной связи со случайной величиной X . Вопрос о том, какую долю линейно обусловленной дисперсии можно считать признаком наличия выраженной корреляционной связи, остается на совести исследователя. Тем не менее, становится ясно, что малые значения коэффициента корреляции (r < 0.3 ) дают настолько малую долю линейно объясненной дисперсии, что бессмысленно говорить о какой бы то ни было выраженной корреляционной связи. При r > 0.5 можно говорить о наличии заметной корреляционной связи между величинами, а при r > 0.7 корреляционная связь может рассматриваться как существенная.
Введение. 2
1. Оценка значимости коэффициентов регрессии и корреляции с помощью f-критерия Стьюдента. 3
2. Расчет значимости коэффициентов регрессии и корреляции с помощью f-критерия Стьюдента. 6
Заключение. 15
После построения уравнения регрессии необходимо сделать проверку его значимости: с помощью специальных критериев установить, не является ли полученная зависимость, выраженная уравнением регрессии, случайной, т.е. можно ли ее использовать в прогнозных целях и для факторного анализа. В статистике разработаны методики строгой проверки значимости коэффициентов регрессии с помощью дисперсионного анализа и расчета специальных критериев (например, F-критерия). Нестрогая проверка может быть выполнена путем расчета среднего относительного линейного отклонения (ё), называемого средней ошибкой аппроксимации:
Перейдем теперь к оценке значимости коэффициентов регрессии bj и построению доверительного интервала для параметров регрессионной модели Ру (J=l,2,..., р).
Блок 5 - оценка значимости коэффициентов регрессий по величине ^-критерия Стьюдента. Расчетные значения ta сравниваются с допустимым значением
Блок 5 - оценка значимости коэффициентов регрессий по величине ^-критерия. Расчетные значения t0n сравниваются с допустимым значением 4,/, которое определяется по таблицам t - распределения для заданной вероятности ошибок (а) и числа степеней свободы (/).
Кроме проверки значимости всей модели, необходимо провести проверки значимости коэффициентов регрессии по /-критерию Стюдента. Минимальное значение коэффициента регрессии Ьг должно соответствовать условию bifob- ^t, где bi - значение коэффициента уравнения регрессии в натуральном масштабе при i-ц факторном признаке; аь. - средняя квадратическая ошибка каждого коэффициента. несопоставимость между собой по своей значимости коэффициентов D;
Дальнейший статистический анализ касается проверки значимости коэффициентов регрессии. Для этого находим значение ^-критерия для коэффициентов регрессии. В результате их сравнения определяется наименьший по величине ^-критерий. Фактор, коэффициенту которого соответствует наименьший ^-критерий, исключается из дальнейшего анализа.
Для оценки статистической значимости коэффициентов регрессии и корреляции рассчитываются t-критерий Стъюдента и доверительные интервалы каждого из показателей. Выдвигается гипотеза Но о случайной природе показателей, т.е. о незначимом их отличии от нуля. Оценка значимости коэффициентов регрессии и корреляции с помощью f-критерия Стьюдента проводится путем сопоставления их значений с величиной случайной ошибки:
Оценка значимости коэффициентов чистой регрессии с помощью /-критерия Стьюдента сводится к вычислению значения
Качество труда - характеристика конкретного труда, отражающая степень его сложности, напряженности (интенсивности), условия и значимость для развития экономики. К.т. измеряется посредством тарифной системы, позволяющей дифференцировать заработную плату в зависимости от уровня квалификации (сложности труда), условий, тяжести труда и его интенсивности, а также значимости отдельных отраслей и производств, районов, территорий для развития экономики страны. К.т. находит выражение в заработной плате работников, складывающейся на рынке труда под воздействием спроса и предложения рабочей силы (конкретные виды труда). К.т. - сложная по структуре
Полученные баллы относительной значимости отдельных экономических, социальных и экологических последствий осуществления проекта дают далее основу для сравнения альтернативных проектов и их вариантов с помощью "комплексного балльного безразмерного критерия социальной и эколого-экономической эффективности" проекта Эк, рассчитываемого (в усредненных баллах значимости) по формуле
Внутриотраслевое регулирование обеспечивает различия в оплате труда работников данной отрасли промышленности в зависимости от значимости отдельных.видов производства данной отрасли, от сложности и условий труда, а также от применяемых форм оплаты труда.
Полученная рейтинговая оценка анализируемого предприятия по отношению к предприятию-эталону без учета значимости отдельных показателей является сравнительной. При сравнении рейтинговых оценок нескольких предприятий наивысший рейтинг имеет предприятие с минимальным значением полученной сравнительной оценки.
Понимание качества товара как меры его полезности ставит практически важный вопрос об её измерении. Его решение достигается изучением значимости отдельных свойств в удовлетворении определенной потребности. Значимость даже одного и того же свойства может быть неодинаковой в зависимости от условий потребления продукта. Следовательно, и полезность товара в разных обстоятельствах её использования различна.
Второй этап работы - изучение статистических данных и выявление взаимосвязи и взаимодействия показателей, определение значимости отдельных факторов и причин изменения общих показателей.
Все рассматриваемые показатели сводятся в один таким образом, что в результате получается комплексная оценка всех анализируемых сторон деятельности предприятия с учетом условий его деятельности, с учетом степени значимости отдельных показателей для различных типов инвесторов:
Коэффициенты регрессии показывают интенсивность влияния факторов на результативный показатель. Если проведена предварительная стандартизация факторных показателей, то Ь0 равняется среднему значению результативного показателя в совокупности. Коэффициенты Ь, Ь2 ..... Ьл показывают, на сколько единиц уровень результативного показателя отклоняется от своего среднего значения, если значения факторного показателя отклоняются от среднего, равного нулю, на одно стандартное отклонение. Таким образом, коэффициенты регрессии характеризуют степень значимости отдельных факторов для повышения уровня результативного показателя. Конкретные значения коэффициентов регрессии определяют по эмпирическим данным согласно методу наименьших квадратов (в результате решения систем нормальных уравнений).
2. Расчет значимости коэффициентов регрессии и корреляции с помощью f-критерия Стьюдента
Рассмотрим линейную форму многофакторных связей не только как наиболее простую, но и как форму, предусмотренную пакетами прикладных программ для ПЭВМ. Если же связь отдельного фактора с результативным признаком не является линейной, то производят линеаризацию уравнения путем замены или преобразования величины факторного признака.
Общий вид многофакторного уравнения регрессии имеет вид:
где k - число факторных признаков.
Чтобы упростить систему уравнений МНК, необходимую для вычисления параметров уравнения (8.32), обычно вводят величины отклонений индивидуальных значений всех признаков от средних величин этих признаков.
Получаем систему k уравнений МНК:

Решая эту систему, получаем значения коэффициентов условно-чистой регрессии b. Свободный член уравнения вычисляется по формуле
Термин «коэффициент условно-чистой регресии» означает, что каждая из величин bj измеряет среднее по совокупности отклонение результативного признака от его средней величины при отклонении данного фактора хj от своей средней величины на единицу его измерения и при условии, что все прочие факторы, входящие в уравнение регрессии, закреплены на средних значениях, не изменяются, не варьируют.
Таким образом, в отличие от коэффициента парной регрессии коэффициент условно-чистой регрессии измеряет влияние фактора, абстрагируясь от связи вариации этого фактора с вариацией остальных факторов. Если было бы возможным включить в уравнение регрессии все факторы, влияющие на вариацию результативного признака, то величины bj. можно было бы считать мерами чистого влияния факторов. Но так как реально невозможно включить все факторы в уравнение, то коэффициенты bj. не свободны от примеси влияния факторов, не входящих в уравнение.
Включить все факторы в уравнение регрессии невозможно по одной из трех причин или сразу по ним всем, так как:
1) часть факторов может быть неизвестна современной науке, познание любого процесса всегда неполное;
2) по части известных теоретических факторов нет информации либо таковая ненадежна;
3) численность изучаемой совокупности (выборки) ограничена, что позволяет включить в уравнение регрессии ограниченное число факторов.
Коэффициенты условно-чистой регрессии bj. являются именованными числами, выраженными в разных единицах измерения, и поэтому несравнимы друг с другом. Для преобразования их в сравнимые относительные показатели применяется то же преобразование, что и для получения коэффициента парной корреляции. Полученную величину называют стандартизованным коэффициентом регрессии или?-коэффициентом.
Коэффициент при факторе хj, определяет меру влияния вариации фактора хj на вариацию результативного признака у при отвлечении от сопутствующей вариации других факторов, входящих в уравнение регрессии.
Коэффициенты условно-чистой регрессии полезно выразить в виде относительных сравнимых показателей связи, коэффициентов эластичности:
Коэффициент эластичности фактора хj говорит о том, что при отклонении величины данного фактора от его средней величины на 1% и при отвлечении от сопутствующего отклонения других факторов, входящих в уравнение, результативный признак отклонится от своего среднего значения на ej процентов от у. Чаще интерпретируют и применяют коэффициенты эластичности в терминах динамики: при увеличении фактора х.на 1% его средней величины результативный признак увеличится на е. процентов его средней величины.
Рассмотрим расчет и интерпретацию уравнения многофакторной регрессии на примере тех же 16 хозяйств (табл. 8.1). Результативный признак - уровень валового дохода и три фактора, влияющих на него, представлены в табл. 8.7.
Напомним еще раз, что для получения надежных и достаточно точных показателей корреляционной связи необходима более многочисленная совокупность.
Таблица 8.7
Уровень валового дохода и его факторы
| Номера хозяйств |
Валовой доход, руб./ra у |
Затраты труда, чел.-дни/га х1 |
Доля пашни, |
Надой молока на 1 корову, |
Таблица 8.8 Показатели уравнения регрессии
| Dependent variable: у |
|||||
| Regression coefficient |
|||||
| Constant-240,112905 |
|||||
| Std. error оf est. = 79,243276 |
|||||
Решение проведено по программе «Microstat» для ПЭВМ. Приведем таблицы из распечатки: табл. 8.7 дает средние величины и средние квадратические отклонения всех признаков. Табл. 8.8 содержит коэффициенты регрессии и их вероятностную оценку:
первая графа «var» - переменные, т. е. факторы; вторая графа «regression coefficient» - коэффициенты условно-чистой регрессии bj; третья графа «std. errror» - средние ошибки оценок коэффициентов регрессии; четвертая графа - значения t-критерия Стьюдента при 12 степенях свободы вариации; пятая графа «prob» - вероятности нулевой гипотезы относительно коэффициентов регрессии;
шестая графа «partial r2» - частные коэффициенты детерминации. Содержание и методика расчета показателей в графах 3-6 рассматриваются далее в главе 8. «Constant» - свободный член уравнения регрессии a; «Std. error of est.» - средняя квадратическая ошибка оценки результативного признака по уравнению регрессии. Было получено уравнение множественной регрессии:
у= 2,26x1 - 4,31х2 + 0,166х3 - 240.
Это означает, что величина валового дохода на 1 га сельхозугодий в среднем по совокупности возрастала на 2,26 руб. при увеличении затрат труда на 1 ч/га; уменьшалась в среднем на 4,31 руб. при возрастании доли пашни в сельхозугодиях на 1% и увеличивалась на 0,166 руб. при росте надоя молока на корову на 1 кг. Отрицательная величина свободного члена вполне закономерна, и, как уже отмечено в п. 8.2, результативный признак - валовой доход становится нулевым задолго до достижения нулевых значений факторов, которое в производстве невозможно.
Отрицательное значение коэффициента при х^ - сигнал о существенном неблагополучии в экономике изучаемых хозяйств, где растениеводство убыточно, а прибыльно только животноводство. При рациональных методах ведения сельского хозяйства и нормальных ценах (равновесных или близких к ним) на продукцию всех отраслей, доход должен не уменьшаться, а возрастать с увеличением наиболее плодородной доли в сельхозугодиях - пашни.
На основе данных предпоследних двух строк табл. 8.7 и табл. 8.8 рассчитаем р-коэффициенты и коэффициенты эластичности согласно формулам (8.34) и (8.35).
Как на вариацию уровня дохода, так и на его возможное изменение в динамике самое сильное влияние оказывает фактор х3 - продуктивность коров, а самое слабое - х2 - доля пашни. Значения Р2/ будут использоваться в дальнейшем (табл. 8.9);
Таблица 8.9 Сравнительное влияние факторов на уровень дохода
| Факторы хj |
|||

Итак, мы получили, что?-коэффициент фактора хj относится к коэффициенту эластичности этого фактора, как коэффициент вариации фактора к коэффициенту вариации результативного признака. Поскольку, как видно по последней строке табл. 8.7, коэффициенты вариации всех факторов меньше коэффициента вариации результативного признака; все?-коэффициенты меньше коэффициентов эластичности.
Рассмотрим соотношение между парным и условно-чистым коэффициентом регрессии на примере фактора -с,. Парное линейное уравнение связи у с х, имеет вид:
y = 3,886x1 – 243,2
Условно-чистый коэффициент регрессии при x1, составляет только 58% парного. Остальные 42% связаны с тем, что вариации x1 сопутствует вариация факторов x2 x3, которая, в свою очередь, влияет на результативный признака. Связи всех признаков и их коэффициенты парных регрессий представлены на графе связей (рис. 8.2).

Если сложить оценки прямого и опосредованного влияния вариации х1 на у, т. е. произведения коэффициентов парных регрессий по всем «путям» (рис. 8.2), получим: 2,26 + 12,55·0,166 + (-0,00128)·(-4,31) + (-0,00128)·17,00·0,166 = 4,344.
Эта величина даже больше парного коэффициента связи x1 с у. Следовательно, косвенное влияние вариации x1 через не входящие в уравнение признаки-факторы - обратное, дающее в сумме:
1 Айвазян С.А., Мхитарян В.С. Прикладная статистика и основы эконометрики. Учебник для вузов. - М.: ЮНИТИ, 2008,– 311с.
2 Джонстон Дж. Эконометрические методы. - М.: Статистика, 1980,. – 282с.
3 Доугерти К. Введение в эконометрику. - М.: ИНФРА-М, 2004, – 354с.
4 Дрейер Н., Смит Г., Прикладной регрессионный анализ. - М.: Финансы и статистика, 2006,– 191с.
5 Магнус Я.Р., Картышев П.К., Пересецкий А.А. Эконометрика. Начальный курс.-М.: Дело, 2006, – 259с.
6 Практикум по эконометрике/Под ред. И.И.Елисеевой.- М.: Финансы и статистика, 2004, – 248с.
7 Эконометрика/Под ред. И.И.Елисеевой.- М.: Финансы и статистика, 2004, – 541с.
8 Кремер Н., Путко Б. Эконометрика.- М.:ЮНИТИ-ДАНА,200, – 281с.
Айвазян С.А., Мхитарян В.С. Прикладная статистика и основы эконометрики. Учебник для вузов. - М.: ЮНИТИ, 2008,–с. 23.
Кремер Н., Путко Б. Эконометрика.- М.:ЮНИТИ-ДАНА,200, –с.64
Дрейер Н., Смит Г., Прикладной регрессионный анализ. - М.: Финансы и статистика, 2006,– с57.
Практикум по эконометрике/Под ред. И.И.Елисеевой.- М.: Финансы и статистика, 2004, –с 172.
| Номер региона | Среднедушевой прожиточный минимум в день одного трудоспособного, руб., х | Среднедневная заработная плата, руб., у |
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
1. Построить линейное уравнение парной регрессии у от х.
2. Рассчитать линейный коэффициент парной корреляции и среднюю ошибку аппроксимации.
3. Оценить статистическую значимость параметров регрессии и корреляции.
4. Выполнить прогноз заработной платы у при прогнозном значении среднедушевого прожиточного минимума х, составляющем 107% от среднего уровня.
5. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал.
Решение
находим с помощью калькулятора .
Использование графического метода
.
Этот метод применяют для наглядного изображения формы связи между изучаемыми экономическими показателями. Для этого в прямоугольной системе координат строят график, по оси ординат откладывают индивидуальные значения результативного признака Y, а по оси абсцисс - индивидуальные значения факторного признака X.
Совокупность точек результативного и факторного признаков называется полем корреляции
.
На основании поля корреляции можно выдвинуть гипотезу (для генеральной совокупности) о том, что связь между всеми возможными значениями X и Y носит линейный характер.
Линейное уравнение регрессии имеет вид y = bx + a + ε
Здесь ε - случайная ошибка (отклонение, возмущение).
Причины существования случайной ошибки:
1. Невключение в регрессионную модель значимых объясняющих переменных;
2. Агрегирование переменных. Например, функция суммарного потребления – это попытка общего выражения совокупности решений отдельных индивидов о расходах. Это лишь аппроксимация отдельных соотношений, которые имеют разные параметры.
3. Неправильное описание структуры модели;
4. Неправильная функциональная спецификация;
5. Ошибки измерения.
Так как отклонения ε i для каждого конкретного наблюдения i – случайны и их значения в выборке неизвестны, то:
1) по наблюдениям x i и y i можно получить только оценки параметров α и β
2) Оценками параметров α и β регрессионной модели являются соответственно величины а и b, которые носят случайный характер, т.к. соответствуют случайной выборке;
Тогда оценочное уравнение регрессии (построенное по выборочным данным) будет иметь вид y = bx + a + ε, где e i – наблюдаемые значения (оценки) ошибок ε i , а и b соответственно оценки параметров α и β регрессионной модели, которые следует найти.
Для оценки параметров α и β - используют МНК (метод наименьших квадратов).
Система нормальных уравнений.
Для наших данных система уравнений имеет вид
Из первого уравнения выражаем а и подставим во второе уравнение
Получаем b = 0.92, a = 76.98
Уравнение регрессии:
y = 0.92 x + 76.98

1. Параметры уравнения регрессии.
Выборочные средние.
Выборочные дисперсии:
Среднеквадратическое отклонение
Коэффициент корреляции
Рассчитываем показатель тесноты связи. Таким показателем является выборочный линейный коэффициент корреляции, который рассчитывается по формуле:
Линейный коэффициент корреляции принимает значения от –1 до +1.
Связи между признаками могут быть слабыми и сильными (тесными). Их критерии оцениваются по шкале Чеддока :
0.1 < r xy < 0.3: слабая;
0.3 < r xy < 0.5: умеренная;
0.5 < r xy < 0.7: заметная;
0.7 < r xy < 0.9: высокая;
0.9 < r xy < 1: весьма высокая;
В нашем примере связь между среднедневной заработной платы и среднедушевым прожиточным минимумом высокая и прямая.
1.2. Уравнение регрессии
(оценка уравнения регрессии).
Линейное уравнение регрессии имеет вид y = 0.92 x + 76.98
Коэффициентам уравнения линейной регрессии можно придать экономический смысл.
Коэффициент b = 0.92 показывает среднее изменение результативного показателя (в единицах измерения у) с повышением или понижением величины фактора х на единицу его измерения. В данном примере с увеличением на 1 руб. среднедушевого прожиточного минимума в день среднедневная заработная плата повышается в среднем на 0.92.
Коэффициент a = 76.98 формально показывает прогнозируемый уровень Среднедневная заработная плата, но только в том случае, если х=0 находится близко с выборочными значениями.
Подставив в уравнение регрессии соответствующие значения х, можно определить выровненные (предсказанные) значения результативного показателя y(x) для каждого наблюдения.
Связь между среднедневной заработной платы и среднедушевого прожиточного минимума в день определяет знак коэффициента регрессии b (если > 0 – прямая связь, иначе - обратная). В нашем примере связь прямая.
Коэффициент эластичности.
Коэффициенты регрессии (в примере b) нежелательно использовать для непосредственной оценки влияния факторов на результативный признак в том случае, если существует различие единиц измерения результативного показателя у и факторного признака х.
Для этих целей вычисляются коэффициенты эластичности и бета - коэффициенты. Коэффициент эластичности находится по формуле:
Он показывает, на сколько процентов в среднем изменяется результативный признак у при изменении факторного признака х на 1%. Он не учитывает степень колеблемости факторов.
Коэффициент эластичности меньше 1. Следовательно, при изменении среднедушевого прожиточного минимума в день на 1%,
среднедневная заработная плата изменится менее чем на 1%. Другими словами - влияние среднедушевого прожиточного минимума Х на среднедневную заработную плату Y не существенно.
Бета – коэффициент
показывает, на какую часть величины своего среднего квадратичного отклонения изменится в среднем значение результативного признака при изменении факторного признака на величину его среднеквадратического отклонения при фиксированном на постоянном уровне значении остальных независимых переменных:
Т.е. увеличение x на величину среднеквадратического отклонения этого показателя приведет к увеличению средней среднедневной заработной платы Y на 0.721 среднеквадратичного отклонения этого показателя.
1.4. Ошибка аппроксимации.
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации.
Поскольку ошибка меньше 15%, то данное уравнение можно использовать в качестве регрессии.
Коэффициент детерминации.
Квадрат (множественного) коэффициента корреляции называется коэффициентом детерминации, который показывает долю вариации результативного признака, объясненную вариацией факторного признака.
Чаще всего, давая интерпретацию коэффициента детерминации, его выражают в процентах.
R 2 = 0.72 2 = 0.5199
т.е. в 51.99 % случаев изменения среднедушевого прожиточного минимума х приводят к изменению среднедневной заработной платы y. Другими словами - точность подбора уравнения регрессии - средняя. Остальные 48.01% изменения среднедневной заработной платы Y объясняются факторами, не учтенными в модели.
| x | y | x 2 | y 2 | x o y | y(x) | (y i -y cp) 2 | (y-y(x)) 2 | (x i -x cp) 2 | |y - y x |:y |
| 78 | 133 | 6084 | 17689 | 10374 | 148,77 | 517,56 | 248,7 | 57,51 | 0,1186 |
| 82 | 148 | 6724 | 21904 | 12136 | 152,45 | 60,06 | 19,82 | 12,84 | 0,0301 |
| 87 | 134 | 7569 | 17956 | 11658 | 157,05 | 473,06 | 531,48 | 2,01 | 0,172 |
| 79 | 154 | 6241 | 23716 | 12166 | 149,69 | 3,06 | 18,57 | 43,34 | 0,028 |
| 89 | 162 | 7921 | 26244 | 14418 | 158,89 | 39,06 | 9,64 | 11,67 | 0,0192 |
| 106 | 195 | 11236 | 38025 | 20670 | 174,54 | 1540,56 | 418,52 | 416,84 | 0,1049 |
| 67 | 139 | 4489 | 19321 | 9313 | 138,65 | 280,56 | 0,1258 | 345,34 | 0,0026 |
| 88 | 158 | 7744 | 24964 | 13904 | 157,97 | 5,06 | 0,0007 | 5,84 | 0,0002 |
| 73 | 152 | 5329 | 23104 | 11096 | 144,17 | 14,06 | 61,34 | 158,34 | 0,0515 |
| 87 | 162 | 7569 | 26244 | 14094 | 157,05 | 39,06 | 24,46 | 2,01 | 0,0305 |
| 76 | 159 | 5776 | 25281 | 12084 | 146,93 | 10,56 | 145,7 | 91,84 | 0,0759 |
| 115 | 173 | 13225 | 29929 | 19895 | 182,83 | 297,56 | 96,55 | 865,34 | 0,0568 |
| 1027 | 1869 | 89907 | 294377 | 161808 | 1869 | 3280,25 | 1574,92 | 2012,92 | 0,6902 |
2. Оценка параметров уравнения регрессии.
2.1. Значимость коэффициента корреляции.
По таблице Стьюдента с уровнем значимости α=0.05 и степенями свободы k=10 находим t крит:
t крит = (10;0.05) = 1.812
где m = 1 - количество объясняющих переменных.
Если t набл > t критич, то полученное значение коэффициента корреляции признается значимым (нулевая гипотеза, утверждающая равенство нулю коэффициента корреляции, отвергается).
Поскольку t набл > t крит, то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициент корреляции статистически - значим.
В парной линейной регрессии t 2 r = t 2 b и тогда проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии.
2.3. Анализ точности определения оценок коэффициентов регрессии.
Несмещенной оценкой дисперсии возмущений является величина:
S 2 y = 157.4922 - необъясненная дисперсия (мера разброса зависимой переменной вокруг линии регрессии).
12.5496 - стандартная ошибка оценки (стандартная ошибка регрессии).
S a - стандартное отклонение случайной величины a.
S b - стандартное отклонение случайной величины b.
2.4. Доверительные интервалы для зависимой переменной.
Экономическое прогнозирование на основе построенной модели предполагает, что сохраняются ранее существовавшие взаимосвязи переменных и на период упреждения.
Для прогнозирования зависимой переменной результативного признака необходимо знать прогнозные значения всех входящих в модель факторов.
Прогнозные значения факторов подставляют в модель и получают точечные прогнозные оценки изучаемого показателя.
(a + bx p ± ε)
где
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X p = 94
(76.98 + 0.92*94 ± 7.8288)
(155.67;171.33)
С вероятностью 95% можно гарантировать, что значения Y при неограниченно большом числе наблюдений не выйдет за пределы найденных интервалов.
2.5. Проверка гипотез относительно коэффициентов линейного уравнения регрессии.
1) t-статистика. Критерий Стьюдента.
Проверим гипотезу H 0 о равенстве отдельных коэффициентов регрессии нулю (при альтернативе H 1 не равно) на уровне значимости α=0.05.
t крит = (10;0.05) = 1.812
Поскольку 3.2906 > 1.812, то статистическая значимость коэффициента регрессии b подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Поскольку 3.1793 > 1.812, то статистическая значимость коэффициента регрессии a подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Доверительный интервал для коэффициентов уравнения регрессии.
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими:
(b - t крит S b ; b + t крит S b)
(0.9204 - 1.812 0.2797; 0.9204 + 1.812 0.2797)
(0.4136;1.4273)
(a - t lang=SV>a)
(76.9765 - 1.812 24.2116; 76.9765 + 1.812 24.2116)
(33.1051;120.8478)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
2) F-статистики. Критерий Фишера.
Проверка значимости модели регрессии проводится с использованием F-критерия Фишера, расчетное значение которого находится как отношение дисперсии исходного ряда наблюдений изучаемого показателя и несмещенной оценки дисперсии остаточной последовательности для данной модели.
Если расчетное значение с k1=(m) и k2=(n-m-1) степенями свободы больше табличного при заданном уровне значимости, то модель считается значимой.
где m – число факторов в модели.
Оценка статистической значимости парной линейной регрессии производится по следующему алгоритму:
1. Выдвигается нулевая гипотеза о том, что уравнение в целом статистически незначимо: H 0: R 2 =0 на уровне значимости α.
2. Далее определяют фактическое значение F-критерия:
где m=1 для парной регрессии.
3. Табличное значение определяется по таблицам распределения Фишера для заданного уровня значимости, принимая во внимание, что число степеней свободы для общей суммы квадратов (большей дисперсии) равно 1 и число степеней свободы остаточной суммы квадратов (меньшей дисперсии) при линейной регрессии равно n-2.
4. Если фактическое значение F-критерия меньше табличного, то говорят, что нет основания отклонять нулевую гипотезу.
В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-α) принимается альтернативная гипотеза о статистической значимости уравнения в целом.
Табличное значение критерия со степенями свободы k1=1 и k2=10, Fkp = 4.96
Поскольку фактическое значение F > Fkp, то коэффициент детерминации статистически значим (Найденная оценка уравнения регрессии статистически надежна).
Критерий корреляции Пирсона – это метод параметрической статистики, позволяющий определить наличие или отсутствие линейной связи между двумя количественными показателями, а также оценить ее тесноту и статистическую значимость. Другими словами, критерий корреляции Пирсона позволяет определить, есть ли линейная связь между изменениями значений двух переменных. В статистических расчетах и выводах коэффициент корреляции обычно обозначается как r xy или R xy .
1. История разработки критерия корреляции
Критерий корреляции Пирсона был разработан командой британских ученых во главе с Карлом Пирсоном (1857-1936) в 90-х годах 19-го века, для упрощения анализа ковариации двух случайных величин. Помимо Карла Пирсона над критерием корреляции Пирсона работали также Фрэнсис Эджуорт и Рафаэль Уэлдон .
2. Для чего используется критерий корреляции Пирсона?
Критерий корреляции Пирсона позволяет определить, какова теснота (или сила) корреляционной связи между двумя показателями, измеренными в количественной шкале. При помощи дополнительных расчетов можно также определить, насколько статистически значима выявленная связь.
Например, при помощи критерия корреляции Пирсона можно ответить на вопрос о наличии связи между температурой тела и содержанием лейкоцитов в крови при острых респираторных инфекциях, между ростом и весом пациента, между содержанием в питьевой воде фтора и заболеваемостью населения кариесом.
3. Условия и ограничения применения критерия хи-квадрат Пирсона
- Сопоставляемые показатели должны быть измерены в количественной шкале (например, частота сердечных сокращений, температура тела, содержание лейкоцитов в 1 мл крови, систолическое артериальное давление).
- Посредством критерия корреляции Пирсона можно определить лишь наличие и силу линейной взаимосвязи между величинами. Прочие характеристики связи, в том числе направление (прямая или обратная), характер изменений (прямолинейный или криволинейный), а также наличие зависимости одной переменной от другой - определяются при помощи регрессионного анализа .
- Количество сопоставляемых величин должно быть равно двум. В случае анализ взаимосвязи трех и более параметров следует воспользоваться методом факторного анализа .
- Критерий корреляции Пирсона является параметрическим , в связи с чем условием его применения служит нормальное распределение сопоставляемых переменных. В случае необходимости корреляционного анализа показателей, распределение которых отличается от нормального, в том числе измеренных в порядковой шкале, следует использовать коэффициент ранговой корреляции Спирмена .
- Следует четко различать понятия зависимости и корреляции. Зависимость величин обуславливает наличие корреляционной связи между ними, но не наоборот.
Например, рост ребенка зависит от его возраста, то есть чем старше ребенок, тем он выше. Если мы возьмем двух детей разного возраста, то с высокой долей вероятности рост старшего ребенка будет больше, чем у младшего. Данное явление и называется зависимостью , подразумевающей причинно-следственную связь между показателями. Разумеется, между ними имеется и корреляционная связь , означающая, что изменения одного показателя сопровождаются изменениями другого показателя.
В другой ситуации рассмотрим связь роста ребенка и частоты сердечных сокращений (ЧСС). Как известно, обе эти величины напрямую зависят от возраста, поэтому в большинстве случаев дети большего роста (а значит и более старшего возраста) будут иметь меньшие значения ЧСС. То есть, корреляционная связь будет наблюдаться и может иметь достаточно высокую тесноту. Однако, если мы возьмем детей одного возраста , но разного роста , то, скорее всего, ЧСС у них будет различаться несущественно, в связи с чем можно сделать вывод о независимости ЧСС от роста.
Приведенный пример показывает, как важно различать фундаментальные в статистике понятия связи и зависимости показателей для построения верных выводов.
4. Как рассчитать коэффициента корреляции Пирсона?
Расчет коэффициента корреляции Пирсона производится по следующей формуле:

5. Как интерпретировать значение коэффициента корреляции Пирсона?
Значения коэффициента корреляции Пирсона интерпретируются исходя из его абсолютных значений. Возможные значения коэффициента корреляции варьируют от 0 до ±1. Чем больше абсолютное значение r xy – тем выше теснота связи между двумя величинами. r xy = 0 говорит о полном отсутствии связи. r xy = 1 – свидетельствует о наличии абсолютной (функциональной) связи. Если значение критерия корреляции Пирсона оказалось больше 1 или меньше -1 – в расчетах допущена ошибка.
Для оценки тесноты, или силы, корреляционной связи обычно используют общепринятые критерии, согласно которым абсолютные значения r xy < 0.3 свидетельствуют о слабой связи, значения r xy от 0.3 до 0.7 - о связи средней тесноты, значения r xy > 0.7 - о сильной связи.
Более точную оценку силы корреляционной связи можно получить, если воспользоваться таблицей Чеддока :
Оценка статистической значимости коэффициента корреляции r xy осуществляется при помощи t-критерия, рассчитываемого по следующей формуле:
![]()
Полученное значение t r сравнивается с критическим значением при определенном уровне значимости и числе степеней свободы n-2. Если t r превышает t крит, то делается вывод о статистической значимости выявленной корреляционной связи.
6. Пример расчета коэффициента корреляции Пирсона
Целью исследования явилось выявление, определение тесноты и статистической значимости корреляционной связи между двумя количественными показателями: уровнем тестостерона в крови (X) и процентом мышечной массы в теле (Y). Исходные данные для выборки, состоящей из 5 исследуемых (n = 5), сведены в таблице.
Как неоднократно отмечалось, для статистического вывода о наличии или отсутствии корреляционной связи между исследуемыми переменными необходимо произвести проверку значимости выборочного коэффициента корреляции. В связи с тем что надежность статистических характеристик, в том числе и коэффициента корреляции, зависит от объема выборки, может сложиться такая ситуация, когда величина коэффициента корреляции будет целиком обусловлена случайными колебаниями в выборке, на основании которой он вычислен. При существенной связи между переменными коэффициент корреляции должен значимо отличаться от нуля. Если корреляционная связь между исследуемыми переменными отсутствует, то коэффициент корреляции генеральной совокупности ρ равен нулю. При практических исследованиях, как правило, основываются на выборочных наблюдениях. Как всякая статистическая характеристика, выборочный коэффициент корреляции является случайной величиной, т. е. его значения случайно рассеиваются вокруг одноименного параметра генеральной совокупности (истинного значения коэффициента корреляции). При отсутствии корреляционной связи между переменными у и х коэффициент корреляции в генеральной совокупности равен нулю. Но из-за случайного характера рассеяния принципиально возможны ситуации, когда некоторые коэффициенты корреляции, вычисленные по выборкам из этой совокупности, будут отличны от нуля.
Могут ли обнаруженные различия быть приписаны случайным колебаниям в выборке или они отражают существенное изменение условий формирования отношений между переменными? Если значения выборочного коэффициента корреляции попадают в зону рассеяния, обусловленную случайным характером самого показателя, то это не является доказательством отсутствия связи. Самое большее, что при этом можно утверждать, сводится к тому, что данные наблюдений не отрицают отсутствия связи между переменными. Но если значение выборочного коэффициента корреляции будет лежать вне упомянутой зоны рассеяния, то делают вывод, что он значимо отличается от нуля, и можно считать, что между переменными у и х существует статистически значимая связь. Используемый для решения этой задачи критерий, основанный на распределении различных статистик, называется критерием значимости.
Процедура проверки значимости начинается с формулировки нулевой гипотезы H 0 . В общем виде она заключается в том, что между параметром выборки и параметром генеральной совокупности нет каких- либо существенных различий. Альтернативная гипотеза H 1 состоит в том, что между этими параметрами имеются существенные различия. Например, при проверке наличия корреляции в генеральной совокупности нулевая гипотеза заключается в том, что истинный коэффициент корреляции равен нулю (Н0 : ρ = 0). Если в результате проверки окажется, что нулевая гипотеза не приемлема, то выборочный коэффициент корреляции r ух значимо отличается от нуля (нулевая гипотеза отвергается и принимается альтернативная Н1). Другими словами, предположение о некоррелированности случайных переменных в генеральной совокупности следует признать необоснованным. И наоборот, если на основе критерия значимости нулевая гипотеза принимается, т. е. r ух лежит в допустимой зоне случайного рассеяния, то нет оснований считать сомнительным предположение о некоррелированности переменных в генеральной совокупности.
При проверке значимости исследователь устанавливает уровень значимости α, который дает определенную практическую уверенность в том, что ошибочные заключения будут сделаны только в очень редких случаях. Уровень значимости выражает вероятность того, что нулевая гипотеза Н0 отвергается в то время, когда она в действительности верна. Ясно, что имеет смысл выбирать эту вероятность как можно меньшей.
Пусть известно распределение выборочной характеристики, являющейся несмещенной оценкой параметра генеральной совокупности. Выбранному уровню значимости α соответствуют под кривой этого распределения заштрихованные площади (см. рис. 24). Незаштрихованная площадь под кривой распределения определяет вероятность Р = 1 - α. Границы отрезков на оси абсцисс под заштрихованными площадями называют критическими значениями, а сами отрезки образуют критическую область, или область отклонения гипотезы.
При процедуре проверки гипотезы выборочную характеристику, вычисленную по результатам наблюдений, сравнивают с соответствующим критическим значением. При этом следует различать одностороннюю и двустороннюю критические области. Форма задания критической области зависит от постановки задачи при статистическом исследовании. Двусторонняя критическая область необходима в том случае, когда при сравнении параметра выборки и параметра генеральной совокупности требуется оценить абсолютную величину расхождения между ними, т. е. представляют интерес как положительные, так и отрицательные разности между изучаемыми величинами. Когда же надо убедиться в том, что одна величина в среднем строго больше или меньше другой, используется односторонняя критическая область (право- или левосторонняя). Вполне очевидно, что для одного и того же критического значения уровень значимости при использовании односторонней критической области меньше, чем при использовании двусторонней. Если распределение выборочной характеристики симметрично,
Рис. 24. Проверка нулевой гипотезы H0
то уровень значимости двусторонней критической области равен α, а односторонней - (см. рис. 24). Ограничимся лишь общей постановкой проблемы. Более подробно с теоретическим обоснованием проверки статистических гипотез можно познакомиться в специальной литературе. Далее мы лишь укажем критерии значимости для различных процедур, не останавливаясь на их построении.
Проверяя значимость коэффициента парной корреляции, устанавливают наличие или отсутствие корреляционной связи между исследуемыми явлениями. При отсутствии связи коэффициент корреляции генеральной совокупности равен нулю (ρ = 0). Процедура проверки начинается с формулировки нулевой и альтернативной гипотез:
Н0 : различие между выборочным коэффициентом корреляцииr и ρ = 0 незначимо,
Н1 : различие междуr и ρ = 0 значимо, и следовательно, между переменнымиу и х имеется существенная связь. Из альтернативной гипотезы следует, что нужно воспользоваться двусторонней критической областью.
В разделе 8.1 уже упоминалось, что выборочный коэффициент корреляции при определенных предпосылках связан со случайной величиной t , подчиняющейся распределению Стьюдента сf = п - 2 степенями свободы. Вычисленная по результатам выборки статистика
сравнивается с критическим значением, определяемым по таблице распределения Стьюдента при заданном уровне значимости α и f = п - 2 степенях свободы. Правило применения критерия заключается в следующем: если |t | >tf ,а , то нулевая гипотеза на уровне значимостиα отвергается, т. е. связь между переменными значима; если |t | ≤tf ,а , то нулевая гипотеза на уровне значимостиαпринимается. Отклонение значенияr от ρ = 0 можно приписать случайной вариации. Данные выборки характеризуют рассматриваемую гипотезу как весьма возможную и правдоподобную, т. е. гипотеза об отсутствии связи не вызывает возражений.
Процедура проверки гипотезы значительно упрощается, если вместо статистики t воспользоваться критическими значениями коэффициента корреляции, которые могут быть определены через квантили распределения Стьюдента путем подстановки в (8.38)t = tf , а иr = ρ f , а:
![]() (8.39)
(8.39)
Существуют подробные таблицы критических значений, выдержка из которых приведена в приложении к данной книге (см. табл. 6). Правило проверки гипотезы в этом случае сводится к следующему: если r > ρ f , а, то можем утверждать, что связь между переменными существенная. Еслиr ≤rf ,а , то результаты наблюдений считаем непротиворечащими гипотезе об отсутствии связи.