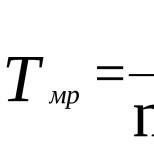Множественная регрессия виды моделей. Модель множественной регрессии
Множественный регрессионный анализ является расширением парного регрессионного анализа. О применяется в тех случаям, когда поведение объясняемой, зависимой переменной необходимо связать с влиянием более чем одной факторной, независимой переменной. Хотя определенная часть многофакторного анализа представляет собой непосредственное обобщение понятий парной регрессионной модели, при выполнении его может возникнуть ряд принципиально новых задач.
Так, при оценке влияния каждой независимой переменной необходимо уметь разграничивать ее воздействие на объясняемую переменную от воздействия других независимых переменных. При этом множественный корреляционный анализ сводится к анализу парных, частных корреляций. На практике обычно ограничиваются определением их обобщенных числовых характеристик, таких как частные коэффициенты эластичности, частные коэффициенты корреляции, стандартизованные коэффициенты множественной регрессии.
Затем решаются задачи спецификации регрессионной модели, одна из которых состоит в определении объема и состава совокупности независимых переменных, которые могут оказывать влияние на объясняемую переменную. Хотя это часто делается из априорных соображений или на основании соответствующей экономической (качественной) теории, некоторые переменные могут в силу индивидуальных особенностей изучаемых объектов не подходить для модели. В качестве наиболее характерных из них можно назвать мультиколлинеарность или автокоррелированность факторных переменных.
3.1. Анализ множественной линейной регрессии с помощью
метода наименьших квадратов (МНК)
В данном разделе полагается, что рассматривается модель регрессии, которая специфицирована правильно. Обратное, если исходные предположения оказались неверными, можно установить только на основании качества полученной модели. Следовательно, этот этап является исходным для проведения множественного регрессионного анализа даже в самом сложном случае, поскольку только он, а точнее его результаты могут дать основания для дальнейшего уточнения модельных представлений. В таком случае выполняются необходимые изменения и дополнения в спецификации модели, и анализ повторяется после уточнения модели до тех пор, пока не будут получены удовлетворительные результаты.
На любой экономический показатель в реальных условиях обычно оказывает влияние не один, а несколько и не всегда независимых факторов. Например, спрос на некоторый вид товара определяется не только ценой данного товара, но и ценами на замещающие и дополняющие товары, доходом потребителей и многими другими факторами. В этом случае вместо парной регрессии M (Y / Х = х ) = f (x ) рассматривается множественная регрессия
M (Y / Х1 = х1, Х2 = х2, …, Хр = Хр ) = f (x 1 , х 2 , …, х р ) (2.1)
Задача оценки статистической взаимосвязи переменных Y и Х 1 , Х 2 , ..., Х Р формулируется аналогично случаю парной регрессии. Уравнение множественной регрессии может быть представлено в виде
Y = f (B , X ) + 2
где X - вектор независимых (объясняющих) переменных; В - вектор параметров уравнения (подлежащих определению); - случайная ошибка (отклонение); Y - зависимая (объясняемая) переменная.
Предполагается, что для данной генеральной совокупности именно функция f связывает исследуемую переменную Y с вектором независимых переменных X .
Рассмотрим самую употребляемую и наиболее простую для статистического анализа и экономической интерпретации модель множественной линейной регрессии. Для этого имеются, по крайней мере, две существенные причины.
Во-первых, уравнение регрессии является линейным, если система случайных величин (X 1 , X 2 , ..., Х Р , Y ) имеет совместный нормальный закон распределения. Предположение о нормальном распределении может быть в ряде случаев обосновано с помощью предельных теорем теории вероятностей. Часто такое предположение принимается в качестве гипотезы, когда при последующем анализе и интерпретации его результатов не возникает явных противоречий.
Вторая причина, по которой линейная регрессионная модель предпочтительней других, состоит в том, что при использовании ее для прогноза риск значительной ошибки оказывается минимальным.
Теоретическое линейное уравнение регрессии имеет вид:
или для индивидуальных наблюдений с номером i :
где i = 1, 2, ..., п.
Здесь В = (b 0 , b 1 ,b Р) - вектор размерности (р+1) неизвестных параметров b j , j = 0, 1, 2, ..., р , называется j -ым теоретическим коэффициентом регрессии (частичным коэффициентом регрессии). Он характеризует чувствительность величины Y к изменению X j . Другими словами, он отражает влияние на условное математическое ожидание M (Y / Х1 = х1, Х2 = х2, …, Хр = x р ) зависимой переменной Y объясняющей переменной Х j при условии, что все другие объясняющие переменные модели остаются постоянными. b 0 - свободный член, определяющий значение Y в случае, когда все объясняющие переменные X j равны нулю.
После выбора линейной функции в качестве модели зависимости необходимо оценить параметры регрессии.
Пусть имеется n наблюдений вектора объясняющих переменных X = (1 , X 1 , X 2 , ..., Х Р ) и зависимой переменной Y :
(1 , х i1 , x i2 , …, x ip , y i ), i = 1, 2, …, n.
Для того чтобы однозначно можно было бы решить задачу отыскания параметров b 0 , b 1 , … , b Р (т.е. найти некоторый наилучший вектор В ), должно выполняться неравенство n > p + 1 . Если это неравенство не будет выполняться, то существует бесконечно много различных векторов параметров, при которых линейная формула связи между X и Y будет абсолютно точно соответствовать имеющимся наблюдениям. При этом, если n = p + 1 , то оценки коэффициентов вектора В рассчитываются единственным образом - путем решения системы p + 1 линейного уравнения:
где i = 1, 2, ..., п.
Например, для однозначного определения оценок параметров уравнения регрессии Y = b о + b 1 X 1 + b 2 X 2 достаточно иметь выборку из трех наблюдений (1 , х i 1 , х i 2 , y i), i = 1, 2, 3. В этом случае найденные значения параметров b 0 , b 1 , b 2 определяют такую плоскость Y = b о + b 1 X 1 + b 2 X 2 в трехмерном пространстве, которая пройдет именно через имеющиеся три точки.
С другой стороны, добавление в выборку к имеющимся трем наблюдениям еще одного приведет к тому, что четвертая точка (х 41 , х 42 , х 43 , y 4) практически всегда будет лежать вне построенной плоскости (и, возможно, достаточно далеко). Это потребует определенной переоценки параметров.
Таким образом, вполне логичен следующий вывод: если число наблюдений больше минимально необходимой величины, т.е. n > p + 1 , то уже нельзя подобрать линейную форму, в точности удовлетворяющую всем наблюдениям. Поэтому возникает необходимость оптимизации, т.е. оценивания параметров b 0 , b 1 , …, b Р , при которых формула регрессии дает наилучшее приближение одновременно для всех имеющихся наблюдений.
В данном случае число = n - p - 1 называется числом степеней свободы. Нетрудно заметить, что если число степеней свободы невелико, то статистическая надежность оцениваемой формулы невысока. Например, вероятность надежного вывода (получения наиболее реалистичных оценок) по трем наблюдениям существенно ниже, чем по тридцати. Считается, что при оценивании множественной линейной регрессии для обеспечения статистической надежности требуется, чтобы число наблюдений превосходило число оцениваемых параметров, по крайней мере, в 3 раза.
Прежде чем перейти к описанию алгоритма нахождения оценок коэффициентов регрессии, отметим желательность выполнимости ряда предпосылок МНК, которые позволят обосновать характерные особенности регрессионного анализа в рамках классической линейной многофакторной модели.
МОДЕЛЬ МНОЖЕСТВЕННОЙ РЕГРЕССИИ
1. ОТБОР ФАКТОРОВ В МОДЕЛЬ МНОЖЕСТВЕННОЙ РЕГРЕССИИ. ОЦЕНКА ПАРАМЕТРОВ МОДЕЛИ
При построении модели множественной регрессии для отображения зависимости между объясняемой переменной Y и независимыми (объясняющими) переменнымиX 1 ,X 2 , …,X k могут использоваться показательная, параболическая и многие другие функции. Однако наибольшее распространение получили модели линейной взаимосвязи, когда факторы входят в модель линейно.
Линейная модель множественной регрессии имеет вид
где k – количество включенных в модель факторов.
Коэффициент регрессии a j показывает, на какую величину в среднем изменится результативный признакY , если переменнуюX j увеличить на единицу измерения, т.е. является нормативным коэффициентом.
Анализ уравнения (1) и методика определения параметров становятся более наглядными, а расчетные процедуры существенно упрощаются, если воспользоваться матричной формой записи уравнения:
где Y – это вектор зависимой переменной размерности, представляющий собойn наблюдений значенийy i ;X – матрицаn наблюдений независимых переменныхX 1 , X 2 , …, X k , размерность матрицыX равна
; а - подлежащий оцениванию вектор неизвестных параметров
Таким образом,
Уравнение (1) содержит значения неизвестных параметров
… . Эти величины оцениваются на основе выборочных
наблюдений, поэтому полученные расчетные показатели не являются истинными, а представляют собой лишь их статистические оценки.
Модель линейной регрессии, в которой вместо истинных значений параметров подставлены их оценки (а именно такие регрессии и применяются на практике), имеет вид

Оценка параметров модели множественной регрессии проводится с помощью метода наименьших квадратов. Формулу для вычисления
параметров регрессионного уравнения приведем без вывода:
Отбор факторов, включаемых в регрессию – один из важнейших этапов построения модели регрессии. Подходы к отбору факторов могут быть разные: один из них основан на анализе матрицы коэффициентов парной корреляции, другой – на процедурах пошагового отбора факторов.
Перед построением модели множественной регрессии вычисляются парные коэффициенты линейной корреляции между всеми исследуемыми переменными Y ,X 1 , X 2 , …, X m , и из них формируется матрица
Вначале анализируют коэффициенты корреляции, отражающие тесноту связи зависимой переменной со всеми включенными в анализ факторами, с целью отсева незначимых переменных.
Затем переходят к анализу остальных столбцов матрицы с целью выявления мультиколлинеарности.
Ситуация, когда два фактора связаны между собой тесной линейной связью (парный коэффициент корреляции между ними превышает по абсолютной величине 0,8), называется коллинеарностью факторов . Коллинеарные факторы фактически дублируют друг друга в модели, существенно ухудшая ее качество.
Наибольшие трудности возникают при наличии мультикоминеарности факторов, когда тесной связью одновременно связаны несколько факторов, т.е. когда нарушается одна из предпосылок регрессионного анализа, состоящая в том, что объясняющие переменные должны быть независимы.
Под мультиколлинеарностью понимается высокая взаимная коррелированность объясняющих переменных, которая приводит к линейной зависимости нормальных уравнений. Мультиколлинеарность может
приводит к невозможности решения соответствующей системы нормальных уравнений и получения оценок параметров регрессионной модели;
стохастической , когда между хотя бы двумя объясняющими переменными существует тесная корреляционная связь. В этом случае определитель матрицы не равен нулю, но очень мал. Экономическая интерпретация параметров уравнения регрессии при этом затруднена, так как некоторые из его коэффициентов могут иметь неправильные с точки зрения экономической теории знаки и неоправданно большие значения. Оценки
параметров ненадежны, обнаруживают большие стандартные ошибки и меняются с изменением объема наблюдений (не только по величине, но и по знаку), что делает модель непригодной для анализа и прогнозирования.
Мультиколлинеарность может возникать в силу разных причин. Например, несколько независимых переменных могут иметь общий временной тренд, относительно которого они совершают малые колебания.
Существует несколько способов для определения наличия или отсутствия мультиколлинеарности:
анализ матрицы коэффициентов парной корреляции. Явление мультиколлинеарности в исходных данных считают установленным, если коэффициент парной корреляции между двумя переменными больше 0,8:
исследование матрицы. Если определитель матрицы близок к нулю, это свидетельствует о наличии мультиколлинеарности.
Для выявления второй ситуации служит тест на мультиколлинеарность Фаррара-Глоубера. С помощью этого теста проверяют, насколько значимо определитель матрицы парных коэффициентов корреляции отличается от единицы. Если он равен нулю, то столбцы матрицыX линейно зависимы и вычислить оценку коэффициентов множественной регрессии по методу наименьших квадратов становится невозможно.
Этот алгоритм содержит три вида статистических критериев проверки наличия мультиколлинеарности:
1) всего массива переменных (критерий «хи-квадрат»);
2) каждой переменной с другими переменными (F -критерий);
3) каждой пары переменных (t -тест).
2) Вычислить наблюдаемое значение статистики Фаррара-Глоубера по формуле
Эта статистика имеет распределение (хи-квадрат).
3) Фактическое значение -критерия сравнить с табличным значением
при 0,5k (k – 1) степенях свободы и уровне значимостиα . ЕслиFG набл больше табличного, то в массиве объясняющих переменных
существует мультиколлинеарность.
2. Проверка наличия мультиколлинеарности каждой переменной другими переменными (F - критерий ):
где c ij – диагональные элементы матрицыC.
3) Фактические значения F -критериев сравнить с табличным значением
при v 1 =k ,v 2 =n – k – 1 степенях свободы и уровне значимостиα , гдеk
– количество факторов. Если F j >F табл , то соответствующая j -я независимая переменная мультиколлинеарна с другими.
3. Проверка наличия мультиколлинеарности каждой пары переменных (t -
тест).
1) Вычислить коэффициент детерминации для каждой переменной:
2) Найти частные коэффициенты корреляции:
где c ij - элемент матрицыС . содержащийся в i -й строке и j -м столбце;c ii иc jj – диагональные элементы матрицыС .
3) Вычислить t -критерии:
4) Фактические значения критериев t ij сравнить с табличнымt табл при (n –
мультиколлинеарность.
Разработаны различные методы устранения или уменьшения мультиколлинеарности. Самый простой из них, но не всегда самый эффективный, состоит в том, что из двух объясняющих переменных, имеющих высокий коэффициент корреляции (больше 0,8), одну переменную исключают из рассмотрения. При этом какую переменную оставить, а какую удалить из анализа, решают исходя из экономических соображений.
Для устранения мультиколлинеарности можно также:
добавить в модель важный фактор для уменьшения дисперсии случайного члена;
изменить или увеличить выборку;
преобразовать мульти коллинеарные переменные и др.
Другой метод устранения или уменьшения мультиколлинеарности – использование стратегии шагового отбора, реализованной в ряде алгоритмов пошаговой регрессии.
Наиболее широкое применение получили следующие схемы построения уравнения множественной регрессии:
метод включения – дополнительное введение фактора;
метод исключения – отсев факторов из полного его набора.
В соответствии с первой схемой признак включается в уравнение в том случае, если его включение существенно увеличивает значение множественного коэффициента корреляции. Это позволяет последовательно отбирать факторы, оказывающие существенное влияние на результативный признак даже в условиях мультиколлинеарности системы признаков, отобранных в качестве аргументов. При этом первым в уравнение включается фактор, наиболее тесно коррелирующий сY вторым – тот фактор, который в паре с первым из отобранных дает максимальное значение множественного коэффициента корреляции, и т.д. Существенно, что на каждом шаге получают новое значение множественного коэффициента (большее, чем на предыдущем шаге); тем самым определяется вклад каждого отобранного фактора в объясненную дисперсиюY.
Вторая схема пошаговой регрессии основана на последовательном исключении факторов с помощью t -критерия. Она заключается в том, что после построения уравнения регрессии и оценки значимости всех коэффициентов регрессии из модели исключают тот фактор, коэффициент при котором незначим и имеет наименьшее по модулю значение t -критерия. После этого получают новое уравнение множественной регрессии и снова производят оценку значимости всех оставшихся коэффициентов регрессии. Если и среди них окажутся незначимые, то опять исключают фактор с наименьшим значением t -критерия. Процесс исключения факторов останавливается на том шаге, при котором все регрессионные коэффициенты значимы.
Ни одна из этих процедур не гарантирует получения оптимального набора переменных. Однако при практическом применении они позволяют получить достаточно хорошие наборы существенно влияющих факторов.
Если это соотношение нарушено, то число степеней свободы остаточной дисперсии очень мало. Это приводит к тому, что параметры уравнения регрессии оказываются статистически незначимыми, а F -критерий меньше табличного значения.
2. ОЦЕНКА КАЧЕСТВА МНОЖЕСТВЕННОЙ РЕГРЕССИИ
Качество модели регрессии проверяется на основе анализа остатков регрессии ε. Анализ остатков позволяет получить представление, насколько хорошо подобрана сама модель и насколько правильно выбран метод опенки коэффициентов. Согласно общим предположениям регрессионного анализа остатки должны вести себя как независимые (в действительности – почти независимые) одинаково распределенные случайные величины.
Исследование полезно начинать с изучения графика остатков. Он может показать наличие какой-то зависимости, не учтенной в модели. Скажем, при подборе простой линейной зависимости междуY иX график
остатков может показать необходимость перехода к нелинейной модели (квадратичной, полиномиальной, экспоненциальной) или включения в модель периодических компонент.
График остатков хорошо показывает и резко отклоняющиеся от модели наблюдения – выбросы. Подобным аномальным наблюдениям надо уделять особо пристальное внимание, так как они могут грубо искажать значения оценок. Чтобы устранить эффект выбросов, надо либо удалить эти точки из анализируемых данных (эта процедура называется цензурированием), либо применять методы оценивания параметров, устойчивые к подобным грубым отклонениям.
Качество модели регрессии оценивается по следующим направлениям:
проверка качества уравнения регрессии;
проверка значимости уравнения регрессии;
анализ статистической значимости параметров модели;
проверка выполнения предпосылок МНК.
Для проверки качества уравнения регрессии вычисляют коэффициент множественной корреляции (индекс корреляции) R и коэффициент детерминацииR 2 . Чем ближе к единице значения этих характеристик, тем выше качество модели.
Ответы на экзаменационные билеты по эконометрике Яковлева Ангелина Витальевна
26. Линейная модель множественной регрессии
Построение модели множественной регрессии является одним из методов характеристики аналитической формы связи между зависимой (результативной) переменной и несколькими независимыми (факторными) переменными.
Модель множественной регрессии строится в том случае, если коэффициент множественной корреляции показал наличие связи между исследуемыми переменными.
Общий вид линейной модели множественной регрессии:
yi=?0+?1x1i+…+?mxmi+?i,
где yi – значение i-ой результативной переменной,
x1i…xmi – значения факторных переменных;
?0…?m – неизвестные коэффициенты модели множественной регрессии;
?i – случайные ошибки модели множественной регрессии.
При построении нормальной линейной модели множественной регрессии учитываются пять условий:
1) факторные переменные x1i…xmi – неслучайные или детерминированные величины, которые не зависят от распределения случайной ошибки модели регрессии ?i;
![]()
3) дисперсия случайной ошибки модели регрессии постоянна для всех наблюдений:
4) между значениями случайных ошибок модели регрессии в любых двух наблюдениях отсутствует систематическая взаимосвязь, т.е. случайные ошибки модели регрессии не коррелированны между собой (ковариация случайных ошибок любых двух разных наблюдений равна нулю):
Это условие выполняется в том случае, если исходные данные не являются временными рядами;
5) на основании третьего и четвёртого условий часто добавляется пятое условие, заключающееся в том, что случайная ошибка модели регрессии – это случайная величина, подчиняющейся нормальному закону распределения с нулевым математическим ожиданием и дисперсией G2: ?i~N(0, G2).
Общий вид нормальной линейной модели парной регрессии в матричной форме:
Y=X* ?+?,

– случайный вектор-столбец значений результативной переменной размерности (n*1);

– матрица значений факторной переменной размерности (n*(m+1)). Первый столбец является единичным, потому что в модели регрессии коэффициент ?0 умножается на единицу;

– вектор-столбец неизвестных коэффициентов модели регрессии размерности ((m+1)*1);

– случайный вектор-столбец ошибок модели регрессии размерности (n*1).
Включение в линейную модель множественной регрессии случайного вектора-столбца ошибок модели обусловлено тем, что практически невозможно оценить связь между переменными со 100-процентной точностью.
Условия построения нормальной линейной модели множественной регрессии, записанные в матричной форме:
1) факторные переменные x1j…xmj
– неслучайные или детерминированные величины, которые не зависят от распределения случайной ошибки модели регрессии ?i
. В терминах матричной записи Х
называется детерминированной матрицей ранга (k+1),
т.е. столбцы матрицы X
линейно независимы между собой и ранг матрицы Х
равен m+1
![]()
2) математическое ожидание случайной ошибки модели регрессии равно нулю во всех наблюдениях:
3) предположения о том, что дисперсия случайной ошибки модели регрессии является постоянной для всех наблюдений и ковариация случайных ошибок любых двух разных наблюдений равна нулю, записываются с помощью ковариационной матрицы случайных ошибок нормальной линейной модели множественной регрессии:

G2 – дисперсия случайной ошибки модели регрессии?;
In – единичная матрица размерности (n*n ).
4) случайная ошибка модели регрессии? является независимой и независящей от матрицы Х случайной величиной, подчиняющейся многомерному нормальному закону распределения с нулевым математическим ожиданием и дисперсией G2: ??N(0;G2In.
В нормальную линейную модель множественной регрессии должны входить факторные переменные, удовлетворяющие следующим условиям:
1) данные переменные должны быть количественно измеримыми;
2) каждая факторная переменная должна достаточно тесно коррелировать с результативной переменной;
3) факторные переменные не должны сильно коррелировать друг с другом или находиться в строгой функциональной зависимости.
Из книги Большая Советская Энциклопедия (ЛИ) автора БСЭ Из книги Пикап. Самоучитель по соблазнению автора Богачев Филипп Олегович Из книги Ответы на экзаменационные билеты по эконометрике автора Яковлева Ангелина Витальевна Из книги автора Из книги автора Из книги автора9. Общая модель парной (однофакторной) регрессии Общая модель парной регрессии характеризует связь между двумя переменными, которая проявляется как некоторая закономерность лишь в среднем в целом по совокупности наблюдений.Регрессионным анализом называется
Из книги автора10. Нормальная линейная модель парной (однофакторной) регрессии Общий вид нормальной (традиционной или классической) линейной модели парной (однофакторной) регрессии (Classical Normal Regression Model):yi=?0+?1xi+?i,где yi– результативные переменные, xi – факторные переменные, ?0, ?1 – параметры
Из книги автора14. Оценка коэффициентов модели парной регрессии с помощью выборочного коэффициента регрессии Помимо метода наименьших квадратов, с помощью которого в большинстве случаев определяются неизвестные параметры модели регрессии, в случае линейной модели парной регрессии
Из книги автора27. Классический метод наименьших квадратов для модели множественной регрессии. Метод Крамера В общем виде линейную модель множественной регрессии можно записать следующим образом:yi=?0+?1x1i+…+?mxmi+?i, где yi – значение i-ой результативной переменной,x1i…xmi – значения факторных
Из книги автора28. Линейная модель множественной регрессии стандартизированного масштаба Помимо классического метода наименьших квадратов для определения неизвестных параметров линейной модели множественной регрессии?0…?m используется метод оценки данных параметров через
Из книги автора31. Частные коэффициенты корреляции для модели множественной регрессии с тремя и более факторными переменными Частные коэффициенты корреляции для модели множественной регрессии с тремя и более факторными переменными позволяют определить степень зависимости между
Из книги автора32. Построение частных коэффициентов корреляции для модели множественной регрессии через показатель остаточной дисперсии и коэффициент множественной детерминации Помимо рекуррентных формул, которые используются для построения частных коэффициентов корреляции для
Из книги автора33. Коэффициент множественной корреляции. Коэффициент множественной детерминации Если частные коэффициенты корреляции модели множественной регрессии оказались значимыми, т. е. между результативной переменной и факторными модельными переменными действительно
Из книги автора35. Проверка гипотезы о значимости коэффициентов регрессии и модели множественной регрессии в целом Проверка значимости коэффициентов регрессии означает проверку основной гипотезы об их значимом отличии от нуля.Основная гипотеза состоит в предположении о незначимости
Из книги автора46. Проверка гипотезы о значимости нелинейной модели регрессии. Проверка гипотезы о линейной зависимости между переменными модели регрессии На нелинейные модели регрессии, которые являются внутренне линейными, т. е. сводимыми к линейному виду, распространяются все
Из книги автора65. Обобщённая модель регрессии. Обобщённый метод наименьших квадратов. Теорема Айткена МНК-оценки неизвестных коэффициентов модели регрессии, чьи случайные ошибки подвержены явлениям гетероскедастичности или автокорреляции, не будут удовлетворять теореме
Если выбранная в качестве объясняющей переменной величина представляет собой действительно доминирующий фактор, то соответствующая парная регрессия достаточно полно описывает механизм причинно-следственной связи. Часто изменение y связано с влиянием не одного, а нескольких факторов. В этом случае в уравнение регрессии вводятся несколько объясняющих переменных. Такая регрессия называется множественной. Уравнение множественной регрессии позволяет лучше, полнее объяснить поведение зависимой переменной, чем парная регрессия, кроме того, оно дает возможность сопоставить эффективность влияния различных факторов.
Линейная модель множественной регрессии имеет вид:
где m – количество включенных в модель факторов. Коэффициент регрессии показывает, на какую величину в среднем изменится результативный признак y , если переменную увеличить на единицу измерения, т.е. является нормативным коэффициентом.
Уравнение линейной модели множественной регрессии в матричном виде имеет вид:
![]() , (7.11)
, (7.11)
где Y n х1 наблюдаемых значений зависимой переменной;
X – матрица размерности n х(m+1) наблюдаемых значений независимых переменных (дополнительно вводится фактор, состоящий из одних единиц для вычисления свободного члена);
α – вектор-столбец размерности (m+1) х1 неизвестных, подлежащих оценке коэффициентов регрессии;
ε – вектор-столбец размерности n х1 случайных отклонений.
Таким образом,
, , ,.
, ,.
При применении МНК относительно случайной составляющей в модели (7.10) принимаются предположения, которые являются аналогами предположений, сделанных выше для МНК, применяемого при оценивании параметров парной регрессии. Обычно предполагается:
1. ![]() - детерминированные переменные.
- детерминированные переменные.
2. ![]() - математическое ожидание случайной составляющей в любом наблюдении равно нулю.
- математическое ожидание случайной составляющей в любом наблюдении равно нулю.
3. - дисперсия случайного члена постоянна для всех наблюдений.
4. - в любых двух наблюдениях отсутствует систематическая связь между значениями случайной составляющей.
5. ~ - часто добавляется условие о нормальности распределения случайного члена.
Модель линейной множественной регрессии, для которой выполняются данные предпосылки, называется классической нормальной регрессионной моделью (Classical Normal Regression model).
Гипотезы, лежащие в основе модели множественной регрессии удобно записать в матричной форме:
1. Х – детерминированная матрица, имеет максимальный ранг (m+1)
, ρ(Х)=m+1
3,4. ![]() , где I n
– единичная матрица размером n
xn
. Так как ε
- вектор-столбец, размерности n
х1
, а ε Т
– вектор-строка, произведение εε Т
есть симметрическая матрица порядка n
. Матрица ковариаций:
, где I n
– единичная матрица размером n
xn
. Так как ε
- вектор-столбец, размерности n
х1
, а ε Т
– вектор-строка, произведение εε Т
есть симметрическая матрица порядка n
. Матрица ковариаций:
 ,
,
Элементы, стоящие на главной диагонали, свидетельствуют о том, что для всех i , это означает, что все имеют постоянную дисперсию . Элементы, не стоящие на главной диагонали дают нам для , так что значения попарно некоррелированы.
1. Основные определения и формулы
Множественная регрессия
- регрессия между переменными и ![]() т.е. модель вида:
т.е. модель вида:
где - зависимая переменная (результативный признак);
![]() - независимые объясняющие переменные;
- независимые объясняющие переменные;
Возмущение или стохастическая переменная, включающая влияние неучтенных в модели факторов;
Число параметров при переменных
Основная цель множественной регрессии - построить модель с большим числом факторов, определив при этом влияние каждого из них в отдельности, а также совокупное их воздействие на моделируемый показатель.
Уравнение множественной линейной регрессии
в случае независимых переменных имеет вид а в случае двух независимых переменных - ![]() (двухфакторное уравнение).
(двухфакторное уравнение).
Для оценки параметров уравнения множественной регрессии применяют метод наименьших квадратов . Строится система нормальных уравнений:

Решение этой системы позволяет получить оценки параметров регрессии с помощью метода определителей
где  - определитель системы;
- определитель системы;
![]() - частные определители, которые получаются путем замены соответствующего столбца матрицы определителя системы данными правой части системы.
- частные определители, которые получаются путем замены соответствующего столбца матрицы определителя системы данными правой части системы.
Для двухфакторного уравнения коэффициенты множественной линейной регрессии можно вычислить по формулам:
![]()
Частные уравнения регрессии
характеризуют изолированное влияние фактора на результат, ибо другие факторы закреплены на неизменном уровне. Эффекты влияния других факторов присоединены в них к свободному члену уравнения множественной регрессии. Это позволяет на основе частных уравнений регрессии ![]() определять частные коэффициенты эластичности
:
определять частные коэффициенты эластичности
:

Средние коэффициентами эластичности показывают на сколько процентов в среднем изменится результат при изменении соответствующего фактора на 1%:
Их можно сравнивать друг с другом и соответственно ранжировать факторы по силе их воздействия на результат.
Тесноту совместного влияния факторов на результат оценивает коэффиц и ент (индекс) множественной корреляции :

Величина индекса множественной корреляции лежит в пределах от 0 до 1 и должна быть больше или равна максимальному парному индексу корреляции: ![]()
Чем ближе значение индекса множественной корреляции к 1, тем теснее связь результативного признака со всем набором исследуемых факторов.
Сравнивая индексы множественной и парной корреляции, можно сделать вывод о целесообразности (величина индекса множественной корреляции существенно отличается от индекса парной корреляции) включения в уравнение регрессии того или иного фактора.
При линейной зависимости совокупный коэффициент множественной ко р реляции определяется через матрицу парных коэффициентов корреляции:

где  - определитель матрицы парных коэффициентов корреляции;
- определитель матрицы парных коэффициентов корреляции;
 - определитель матрицы межфакторной корреляции.
- определитель матрицы межфакторной корреляции.
Частны е коэффициент ы корреляции характеризуют тесноту линейной зависимости между результатом и соответствующим фактором при устранении влияния других факторов. Если вычисляется, например, (частный коэффициент корреляции между и при фиксированном влиянии ), это означает, что определяется количественная мера линейной зависимости между и которая будет иметь место, если устранить влияние на эти признаки фактора
Частные коэффициенты корреляции, измеряющие влияние на фактора при неизменном уровне других факторов, можно определить как:

или по рекуррентной формуле:

Для двухфакторного уравнения:

 или
или


Частные коэффициенты корреляции изменяются в пределах от -1 до +1.
Сравнение значений парного и частного коэффициентов корреляции показывает направление воздействия фиксируемого фактора. Если частный коэффициент корреляции получится меньше, чем соответствующий парныйкоэффициент значит взаимосвязь признаков и в некоторой степени обусловлена воздействием на них фиксируемой переменной И наоборот, большее значение частного коэффициента по сравнению с парным свидетельствует о том, что фиксируемая переменная ослабляет своим воздействием связь и
Порядок частного коэффициента корреляции определяется количеством факторов, влияние которых исключается. Например, - коэффициент частной корреляции первого порядка.
Зная частные коэффициенты корреляции (последовательно первого, второго и более высокого порядка), можно определить совокупный коэффициент мн о жественной корреляции :
Качество построенной модели в целом оценивает коэффициент (индекс) множественной детерминации , который рассчитывается как квадрат индекса множественной корреляции: Индекс множественной детерминации фиксирует долю объясненной вариации результативного признака за счет рассматриваемых в регрессии факторов. Влияние других, не учтенных в модели факторов, оценивается как
Если число параметров при близко к объему наблюдений, то коэффициент множественной корреляции приблизится к единице даже при слабой связи факторов с результатом. Для того чтобы не допустить возможногопреувеличения тесноты связи, используется скорректированный индекс множественной корреляции , который содержит поправку на число степеней свободы:

Чем больше величина тем сильнее различия и
Значимость частных коэффициентов корреляции проверяется аналогично случаю парных коэффициентов корреляции. Единственным отличием является число степеней свободы, которое следует брать равным =--2.
Значимость уравнения множественной регрессии в целом , так же как и в парной регрессии, оценивается с помощью - критерия Фишера :

Мерой для оценки включения фактора в модель служит частный -критерий . В общем виде для фактора частный -критерий определяется как

Для двухфакторного уравнения частные -критерии имеют вид:


Если фактическое значение превышает табличное, то дополнительное включение фактора в модель статистически оправданно и коэффициент чистой регрессии при факторе статистически значим. Если же фактическое значение меньше табличного, то фактор нецелесообразно включать в модель, а коэффициент регрессии при данном факторе в этом случае статистически незначим.
Для оценки значимости коэффициентов чистой регрессии по -критерию Стьюдента используется формула:

где - коэффициент чистой регрессии при факторе
- средняя квадратическая (стандартная) ошибка коэффициента регрессии которая может быть определена по формуле:

При дополнительном включении в регрессию нового фактора коэффициент детерминации должен возрастать, а остаточная дисперсия уменьшаться. Если это не так, то включаемый в анализ новый фактор не улучшает модель и практически является лишним фактором. Насыщение модели лишними факторами не только не снижает величину остаточной дисперсии и не увеличивает показатель детерминации, но и приводит к статистической незначимости параметров регрессии по -критерию Стьюдента.
При построении уравнения множественной регрессии может возникнуть проблема мультиколлинеарности факторов. Считается, что две переменные явно коллинеарны, т.е. находятся между собой в линейной зависимости, если Если факторы явно коллинеарны, то они дублируют друг друга и один из них рекомендуется исключить из регрессии. Предпочтение при этом отдается не фактору, более тесно связанному с результатом, а тому фактору, который при достаточно тесной связи с результатом имеет наименьшую тесноту связи с другими факторами.
Для оценки мультиколлинеарности факторов может использоваться опред е литель матрицы между факторами . Чем ближе к 0 определитель матрицы межфакторной корреляции, тем сильнее мультиколлинеарность факторов и ненадежнее результаты множественной регрессии. И наоборот, чем ближе к 1 определитель, тем меньше мультиколлинеарность факторов.
Для применения МНК требуется, чтобы дисперсия остатков была гомоскедастичной. Это означает, что для каждого значения фактора остатки ![]() имеют одинаковую дисперсию. Если это условие применения МНК не соблюдается, то имеет место гетероскедастичность
. При нарушении гомоскедастичности выполняются неравенства
имеют одинаковую дисперсию. Если это условие применения МНК не соблюдается, то имеет место гетероскедастичность
. При нарушении гомоскедастичности выполняются неравенства ![]()
Наличие гетероскедастичности можно наглядно видеть из поля корреляции (рис. 9.22).



Рис. 9.22 . Примеры гетероскедастичности:
а) дисперсия остатков растет по мере увеличения
б) дисперсия остатков достигает максимальной величины при средних значениях переменной и уменьшается при минимальных и максимальных значениях
в) максимальная дисперсия остатков при малых значениях и дисперсия остатков однородна по мере увеличения значений
Для проверки выборки на гетероскедастичность можно использовать метод Гольдфельда-Квандта (при малом объеме выборки) или критерий Бартлетта (при большом объеме выборки).
Последовательность применения теста Гольдфельда-Квандта :
1) Упорядочить данные по убыванию той независимой переменной, относительно которой есть подозрение на гетероскедастичность.
2) Исключить из рассмотрения центральных наблюдений. При этом ![]() где - число оцениваемых параметров. Из экспериментальных расчетов для случая однофакторного уравнения регрессии рекомендовано при =30 принимать =8, а при =60 соответственно =16.
где - число оцениваемых параметров. Из экспериментальных расчетов для случая однофакторного уравнения регрессии рекомендовано при =30 принимать =8, а при =60 соответственно =16.
3) Разделить совокупность из наблюдений на две группы (соответственно с малыми и большими значениями фактора ) и определить по каждой из групп уравнение регрессии.
4) Вычислить остаточную сумму квадратов для первой и второй групп и найти их отношение ![]() где При выполнении нулевой гипотезы о гомоскедастичности отношение будет удовлетворять -критерию Фишера со степенями свободы
где При выполнении нулевой гипотезы о гомоскедастичности отношение будет удовлетворять -критерию Фишера со степенями свободы ![]() для каждой остаточной суммы квадратов. Чем больше величина превышает тем более нарушена предпосылка о равенстве дисперсий остаточных величин.
для каждой остаточной суммы квадратов. Чем больше величина превышает тем более нарушена предпосылка о равенстве дисперсий остаточных величин.
Если необходимо включить в модель факторы, имеющие два или более качественных уровней (пол, профессия, образование, климатические условия, принадлежность к определенному региону и т.д.), то им должны быть присвоены цифровые метки, т.е. качественные переменные преобразованы в количественные. Такого вида сконструированные переменные называют фиктивными (и с кусственными) переменными .
К оэффициент регрессии при фиктивной переменной интерпретируется как среднее изменение зависимой переменной при переходе от одной категории к другой при неизменных значениях остальных параметров. Значимость влияния фиктивной переменной проверяется с помощью -критерия Стьюдента.
2. Решение типовых задач
Пример 9. 2. По 15 предприятиям отрасли (табл. 9.4) изучается зависимость затрат на выпуск продукции (тыс. ден. ед.) от объема произведенной продукции (тыс. ед.) и расходов на сырье (тыс. ден. ед). Необходимо:
1) Построить уравнение множественной линейной регрессии.
2) Вычислить и интерпретировать:
Средние коэффициенты эластичности;
Парные коэффициенты корреляции, оценить их значимость на уровне 0,05;
Частные коэффициенты корреляции;
Коэффициент множественной корреляции, множественный коэффициент детерминации, скорректированный коэффициент детерминации.
3) Оценить надежность построенного уравнения регрессии и целесообразность включения фактора после фактора и после
Таблица 9.4
|
x 1 |
x 2 |
||
Решение:
1) В Excel составим вспомогательную таблицу рис. 9.23.

Рис. 9.23 . Расчетная таблица многофакторной регрессии.
С помощью встроенных функций вычислим: =345,5; =13838,89; =8515,78; =219,315; =9,37; =6558,08.
Затем найдем коэффициенты множественной линейной регрессии и оформим вывод результатов как на рис. 9.24.

Рис. 9.24 . Решение задачи в MS Excel
Для вычисления значения коэффициента используем формулы
![]()
Формулы для вычисления параметров заносим в ячейки Е 20 , Е 2 1, Е 2 2. Так длявычисления параметра b 1 в Е 20 поместим формулу =(B20*B24-B21*B22)/(B23*B24-B22^2) и получим 29,83. Аналогично получаем значения =0,301 и Коэффициент =-31,25 (рис. 9.25.).

Рис. 9.25 . Вычисление параметров уравнения множественной регрессии (в с т роке формул формула для расчета b 2) .
Уравнение множественной линейной регрессии примет вид:
31,25+29,83+0,301
Таким образом, при увеличении объема произведенной продукции на 1 тыс. ед. затраты на выпуск этой продукции в среднем увеличатся на 29,83 тыс. ден. ед., а при увеличении расходов на сырье на 1 тыс. ден. ед. затраты увеличатся в среднем на 0,301 тыс. ден. ед.
2) Для вычисления средних коэффициентов эластичности воспользуемся формулой: Вычисляем: =0,884 и =0,184. Т.е. увеличение только объема произведенной продукции (от своего среднего значения) или только расходов на сырье на 1% увеличивает в среднем затраты на выпуск продукции на 0,884% или 0,184% соответственно. Таким образом, фактор оказывает большее влияние на результат, чем фактор
Для вычисления парных коэффициентов корреляции воспользуемся функцией «КОРРЕЛ» рис. 9.26.

Рис. 9.26 . Вычисление парных коэффициентов корреляции
Значения парных коэффициентов корреляции указывают на весьма тесную связь с и на тесную связь с В то же время межфакторная связь очень сильная (=0,88>0,7), что говорит о том, что один из факторов является неинформативным, т.е. в модель необходимо включать или или
З начимост ь парных коэффициентов корреляции оценим с помощью -критерия Стьюдента. =2,1604 определяем с помощью встроенной статистической функции СТЬЮДРАСПОБР взяв =0,05 и =-2=13.
Фактическое значение -критерия Стьюдента для каждого парного коэффициента определим по формулам: 

 . Результат расчета представлен на рис. 9.27.
. Результат расчета представлен на рис. 9.27.

Рис. 9.27 . Результат расчета фактических значений -критерия Стьюдента
Получим =12,278; =7,1896; =6,845.
Так как фактические значения -статистики превосходят табличные, то парные коэффициенты корреляции не случайно отличаются от нуля, а статистически значимы.



Получим =0,81; =0,34; =0,21. Таким образом, фактор оказывает более сильное влияние на результат, чем
При сравнении значений коэффициентов парной и частной корреляции приходим к выводу, что из-за сильной межфакторной связи коэффициенты парной и частной корреляции отличаются довольно значительно.
Коэффициент множественной корреляции
Следовательно, зависимость от и характеризуется как очень тесная, в которой =93% вариации затрат на выпуск продукции определяются вариацией учтенных в модели факторов: объема произведенной продукции и расходов на сырье. Прочие факторы, не включенные в модель, составляют соответственно 7% от общей вариации
Скорректированный коэффициент множественной детерминации
 =0,9182 указывает на тесную связь между результатом и признаками.
=0,9182 указывает на тесную связь между результатом и признаками.

Рис. 9.28 . Результаты расчета частных коэффициентов корреляции и коэфф и циента множественной корреляции
3) Оценим надежность уравнения регрессии в целом
с помощью -критерия Фишера. Вычислим ![]() . =3,8853 определяем взяв =0,05, =2, =15-2-1=12 помощью встроенной статистической функции FРАСПОБР
с такими же параметрами.
. =3,8853 определяем взяв =0,05, =2, =15-2-1=12 помощью встроенной статистической функции FРАСПОБР
с такими же параметрами.
Так как фактическое значение больше табличного, то с вероятностью 95% делаем заключение о статистической значимости уравнения множественной линейной регрессии в целом.
Оценим целесообразность включения фактора после фактора и после с помощью частного -критерия Фишера по формулам
 ;
;  .
.
Для этого в ячейку B32 заносим формулу для расчета F x 1 «=(B28- H24^2)*(15-3)/(1-B28) », а в ячейку B 33 формулу для расчета F x 2 «=(B28-H23^2)*(15-3)/(1-B28) », результат вычисления F x 1 = 22,4127, F x 2 = 1,5958. Табличное значение критерия Фишера определим с помощью встроенной функции FРАСПОБР с параметрами =0,05, =1, =12 «=FРАСПОБР(0,05; 1 ;12) », результат - =4,747. Так как =22,4127>=4,747, а =1,5958<=4,747, то включение фактора в модель статистически оправдано и коэффициент чистой регрессии статистически значим, а дополнительное включение фактора после того, как уже введен фактор нецелесообразно (рис. 9.29).

Рис. 9.29 . Результаты расчета критерия Фишера
Низкое значение (немногим больше 1) свидетельствует о статистической незначимости прироста за счет включения в модель фактора после фактора Это означает, что парная регрессионная модель зависимости затрат на выпуск продукции от объема произведенной продукции является достаточно статистически значимой, надежной и что нет необходимости улучшать ее, включая дополнительный фактор (расходы на сырье).
3. Дополнительные сведения для решения задач с помощью MS Excel
Сводные данные основных характеристик для одного или нескольких массивов данных можно получить с помощью инструмента анализа данных Опис а тельная статистика . Порядок действий следующий:
1. Необходимо проверить доступ к Пакету анализа . Для этого в ленте выбираем вкладку «Данные», в ней раздел «Анализ» (рис. 9.30.).


Рис. 9.30 . Вкладка данные диалоговое окно «Анализ данных»
2. В диалоговом окне «Анализ данных» выбрать Описательная стат и стика и нажать кнопку «ОК», в появившемся диалоговом окне заполните необходимые поля (рис. 9.31):

Рис.
9.31
.
Диалоговое окно ввода параметров инструмента
«
Описательная статистика
»
Входной интервал - диапазон, содержащий данные результативного и объясняющих признаков;
Группирование - указать, как расположены данные (в столбцах или строках);
Метки - флажок, который указывает, содержит ли первая строка названия столбцов или нет;
Выходной интервал - достаточно указать левую верхнюю ячейку будущего диапазона;
Новый рабочий лист - можно задать произвольное имя нового листа, на который будут выведены результаты.
Для получения информации Итоговой статистики, Уровня наде ж ности, -го наибольшего и наименьшего значений нужно установить соответствующие флажки в диалоговом окне.
Получаем следующую статистику (рис. 2.10).