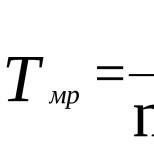Линейный коэффициент корреляции формула статистика. Линейный и множественный коэффициенты корреляции. Сущность и экономическая интерпретация. Пример расчета коэффициента корреляции Пирсона
Коэффициент корреляции (или линейный коэффициент корреляции) обозначается как «r» (в редких случаях как «ρ») и характеризует линейную корреляцию (то есть взаимосвязь, которая задается некоторым значением и направлением) двух или более переменных. Значение коэффициента лежит между -1 и +1, то есть корреляция бывает как положительной, так и отрицательной. Если коэффициент корреляции равен -1, имеет место идеальная отрицательная корреляция; если коэффициент корреляции равен +1, имеет место идеальная положительная корреляция. В остальных случаях между двумя переменными наблюдается положительная корреляция, отрицательная корреляция или отсутствие корреляции. Коэффициент корреляции можно вычислить вручную, с помощью бесплатных онлайн-калькуляторов или с помощью хорошего графического калькулятора.
Шаги
Вычисление коэффициента корреляции вручную
- Например, даны четыре пары значений (чисел) переменных «х» и «у». Можно создать следующую таблицу:
- x || y
- 1 || 1
- 2 || 3
- 4 || 5
- 5 || 7
-
Вычислите среднее арифметическое «х». Для этого сложите все значения «х», а затем полученный результат разделите на количество значений.
- В нашем примере даны четыре значения переменной «х». Чтобы вычислить среднее арифметическое «х», сложите эти значения, а затем сумму разделите на 4. Вычисления запишутся так:
- μ x = (1 + 2 + 4 + 5) / 4 {\displaystyle \mu _{x}=(1+2+4+5)/4}
- μ x = 12 / 4 {\displaystyle \mu _{x}=12/4}
- μ x = 3 {\displaystyle \mu _{x}=3}
-
Найдите среднее арифметическое «у». Для этого выполните аналогичные действия, то есть сложите все значения «у», а затем сумму разделите на количество значений.
- В нашем примере даны четыре значения переменной «у». Сложите эти значения, а затем сумму разделите на 4. Вычисления запишутся так:
- μ y = (1 + 3 + 5 + 7) / 4 {\displaystyle \mu _{y}=(1+3+5+7)/4}
- μ y = 16 / 4 {\displaystyle \mu _{y}=16/4}
- μ y = 4 {\displaystyle \mu _{y}=4}
-
Вычислите стандартное отклонение «х». Вычислив средние значения «х» и «у», найдите стандартные отклонения этих переменных. Стандартное отклонение вычисляется по следующей формуле:
- σ x = 1 n − 1 Σ (x − μ x) 2 {\displaystyle \sigma _{x}={\sqrt {{\frac {1}{n-1}}\Sigma (x-\mu _{x})^{2}}}}
- σ x = 1 4 − 1 ∗ ((1 − 3) 2 + (2 − 3) 2 + (4 − 3) 2 + (5 − 3) 2) {\displaystyle \sigma _{x}={\sqrt {{\frac {1}{4-1}}*((1-3)^{2}+(2-3)^{2}+(4-3)^{2}+(5-3)^{2})}}}
- σ x = 1 3 ∗ (4 + 1 + 1 + 4) {\displaystyle \sigma _{x}={\sqrt {{\frac {1}{3}}*(4+1+1+4)}}}
- σ x = 1 3 ∗ (10) {\displaystyle \sigma _{x}={\sqrt {{\frac {1}{3}}*(10)}}}
- σ x = 10 3 {\displaystyle \sigma _{x}={\sqrt {\frac {10}{3}}}}
- σ x = 1 , 83 {\displaystyle \sigma _{x}=1,83}
-
Вычислите стандартное отклонение «у». Выполните действия, которые описаны в предыдущем шаге. Воспользуйтесь той же формулой, но подставьте в нее значения «у».
- В нашем примере вычисления запишутся так:
- σ y = 1 4 − 1 ∗ ((1 − 4) 2 + (3 − 4) 2 + (5 − 4) 2 + (7 − 4) 2) {\displaystyle \sigma _{y}={\sqrt {{\frac {1}{4-1}}*((1-4)^{2}+(3-4)^{2}+(5-4)^{2}+(7-4)^{2})}}}
- σ y = 1 3 ∗ (9 + 1 + 1 + 9) {\displaystyle \sigma _{y}={\sqrt {{\frac {1}{3}}*(9+1+1+9)}}}
- σ y = 1 3 ∗ (20) {\displaystyle \sigma _{y}={\sqrt {{\frac {1}{3}}*(20)}}}
- σ y = 20 3 {\displaystyle \sigma _{y}={\sqrt {\frac {20}{3}}}}
- σ y = 2 , 58 {\displaystyle \sigma _{y}=2,58}
-
Запишите основную формулу для вычисления коэффициента корреляции. В эту формулу входят средние значения, стандартные отклонения и количество (n) пар чисел обеих переменных. Коэффициент корреляции обозначается как «r» (в редких случаях как «ρ»). В этой статье используется формула для вычисления коэффициента корреляции Пирсона.
- Здесь и в других источниках величины могут обозначаться по-разному. Например, в некоторых формулах присутствуют «ρ» и «σ», а в других «r» и «s». В некоторых учебниках приводятся другие формулы, но они являются математическими аналогами приведенной выше формулы.
-
Вы вычислили средние значения и стандартные отклонения обеих переменных, поэтому можно воспользоваться формулой для вычисления коэффициента корреляции. Напомним, что «n» – это количество пар значений обеих переменных. Значение других величин были вычислены ранее.
- В нашем примере вычисления запишутся так:
- ρ = (1 n − 1) Σ (x − μ x σ x) ∗ (y − μ y σ y) {\displaystyle \rho =\left({\frac {1}{n-1}}\right)\Sigma \left({\frac {x-\mu _{x}}{\sigma _{x}}}\right)*\left({\frac {y-\mu _{y}}{\sigma _{y}}}\right)}
- ρ = (1 3) ∗ {\displaystyle \rho =\left({\frac {1}{3}}\right)*}
[
(1 − 3 1 , 83) ∗ (1 − 4 2 , 58) + (2 − 3 1 , 83) ∗ (3 − 4 2 , 58) {\displaystyle \left({\frac {1-3}{1,83}}\right)*\left({\frac {1-4}{2,58}}\right)+\left({\frac {2-3}{1,83}}\right)*\left({\frac {3-4}{2,58}}\right)}
+ (4 − 3 1 , 83) ∗ (5 − 4 2 , 58) + (5 − 3 1 , 83) ∗ (7 − 4 2 , 58) {\displaystyle +\left({\frac {4-3}{1,83}}\right)*\left({\frac {5-4}{2,58}}\right)+\left({\frac {5-3}{1,83}}\right)*\left({\frac {7-4}{2,58}}\right)} ] - ρ = (1 3) ∗ (6 + 1 + 1 + 6 4 , 721) {\displaystyle \rho =\left({\frac {1}{3}}\right)*\left({\frac {6+1+1+6}{4,721}}\right)}
- ρ = (1 3) ∗ 2 , 965 {\displaystyle \rho =\left({\frac {1}{3}}\right)*2,965}
- ρ = (2 , 965 3) {\displaystyle \rho =\left({\frac {2,965}{3}}\right)}
- ρ = 0 , 988 {\displaystyle \rho =0,988}
-
Проанализируйте полученный результат. В нашем примере коэффициент корреляции равен 0,988. Это значение некоторым образом характеризует данный набор пар чисел. Обратите внимание на знак и величину значения.
- Так как значение коэффициента корреляции положительно, между переменными «х» и «у» имеет место положительная корреляция. То есть при увеличении значения «х», значение «у» тоже увеличивается.
- Так как значение коэффициента корреляции очень близко к +1, значения переменных «х» и «у» сильно взаимосвязаны. Если нанести точки на координатную плоскость, они расположатся близко к некоторой прямой.
Использование онлайн-калькуляторов для вычисления коэффициента корреляции
-
В интернете найдите калькулятор для вычисления коэффициента корреляции. Этот коэффициент довольно часто вычисляется в статистике. Если пар чисел много, вычислить коэффициент корреляции вручную практически невозможно. Поэтому существуют онлайн-калькуляторы для вычисления коэффициента корреляции. В поисковике введите «коэффициент корреляции калькулятор» (без кавычек).
-
Введите данные. Ознакомьтесь с инструкциями на сайте, чтобы правильно ввести данные (пары чисел). Крайне важно вводить соответствующие пары чисел; в противном случае вы получите неверный результат. Помните, что на разных веб-сайтах различные форматы ввода данных.
- Например, на сайте http://ncalculators.com/statistics/correlation-coefficient-calculator.htm значения переменных «х» и «у» вводятся в двух горизонтальных строках. Значения разделяются запятыми. То есть в нашем примере значения «х» вводятся так: 1,2,4,5, а значения «у» так: 1,3,5,7.
- На другом сайте, http://www.alcula.com/calculators/statistics/correlation-coefficient/ , данные вводятся по вертикали; в этом случае не перепутайте соответствующие пары чисел.
-
Вычислите коэффициент корреляции. Введя данные, просто нажмите на кнопку «Calculate», «Вычислить» или аналогичную, чтобы получить результат.
Использование графического калькулятора
-
Введите данные. Возьмите графический калькулятор, перейдите в режим статистических вычислений и выберите команду «Edit» (Редактировать).
- На разных калькуляторах нужно нажимать различные клавиши. В этой статье рассматривается калькулятор Texas Instruments TI-86.
- Чтобы перейти в режим статистических вычислений, нажмите – Stat (над клавишей «+»). Затем нажмите F2 – Edit (Редактировать).
-
Удалите предыдущие сохраненные данные. В большинстве калькуляторов введенные статистические данные хранятся до тех пор, пока вы не сотрете их. Чтобы не спутать старые данные с новыми, сначала удалите любую сохраненную информацию.
- С помощью клавиш со стрелками переместите курсор и выделите заголовок «xStat». Затем нажмите Clear (Очистить) и Enter (Ввести), чтобы удалить все значения, введенные в столбец xStat.
- С помощью клавиш со стрелками выделите заголовок «yStat». Затем нажмите Clear (Очистить) и Enter (Ввести), чтобы удалить все значения, введенные в столбец уStat.
-
Введите исходные данные. С помощью клавиш со стрелками переместите курсор в первую ячейку под заголовком «xStat». Введите первое значение и нажмите Enter. В нижней части экрана отобразится «xStat (1) = __», где вместо пробела будет стоять введенное значение. После того как вы нажмете Enter, введенное значение появится в таблице, а курсор переместится на следующую строку; при этом в нижней части экрана отобразится «xStat (2) = __».
- Введите все значения переменной «х».
- Введя все значения переменной «х», с помощью клавиш со стрелками перейдите в столбец yStat и введите значения переменной «у».
- После ввода всех пар чисел нажмите Exit (Выйти), чтобы очистить экран и выйти из режима статистических вычислений.
-
Вычислите коэффициент корреляции. Он характеризует, насколько близко данные расположены к некоторой прямой. Графический калькулятор может быстро определить подходящую прямую и вычислить коэффициент корреляции.
- Нажмите Stat (Статистика) – Calc (Вычисления). На TI-86 нужно нажать – – .
- Выберите функцию «Linear Regression» (Линейная регрессия). На TI-86 нажмите , которая обозначена как «LinR». На экране отобразится строка «LinR _» с мигающим курсором.
- Теперь введите имена двух переменных: xStat и yStat.
- На TI-86 откройте список имен; для этого нажмите – – .
- В нижней строке экрана отобразятся доступные переменные. Выберите (для этого, скорее всего, нужно нажать F1 или F2), введите запятую, а затем выберите .
- Нажмите Enter, чтобы обработать введенные данные.
-
Проанализируйте полученные результаты. Нажав Enter, на экране отобразится следующая информация:
- y = a + b x {\displaystyle y=a+bx} : это функция, которая описывает прямую. Обратите внимание, что функция записана не в стандартной форме (у = kх + b).
- a = {\displaystyle a=} . Это координата «у» точки пересечения прямой с осью Y.
- b = {\displaystyle b=} . Это угловой коэффициент прямой.
- corr = {\displaystyle {\text{corr}}=} . Это коэффициент корреляции.
- n = {\displaystyle n=} . Это количество пар чисел, которое было использовано в вычислениях.
-
Соберите данные. Перед тем как приступить к вычислению коэффициента корреляции, изучите данные пары чисел. Лучше записать их в таблицу, которую можно расположить вертикально или горизонтально. Каждую строку или столбец обозначьте как «х» и «у».
Коэффициент корреляции - это мера линейной зависимости двух случайных величин в теории вероятностей и статистике. Некоторые виды коэффициентов корреляции могут быть положительными или отрицательными. В первом случае предполагается, что мы можем определить только наличие или отсутствие связи, а во втором - также и её направление.
Случайная величина в теории вероятности
Коэффициент корреляции - это статистический показатель, показывающий, насколько связаны между собой колебания значений двух других показателей. Например, насколько движение доходности ПИФа связано, перекликается (коррелирует) с движением индекса, выбранного для расчета коэффициента бета для этого ПИФа. Чем ближе значение коэффициента корреляции к 1, тем больше коррелируют ПИФ и индекс, а значит коэффициент бета и, следовательно, коэффициент альфа можно принимать к рассмотрению. Если значение этого коэффициента корреляции меньше 0,75, то указанные показатели бессмысленны.

Круговорот случайных величин
Корреляционный анализ занимается степенью связи между двумя случайными величинами Х и Y.
Корреляционный анализ экспериментальных данных для двух случайных величин заключает в себе следующие основные приемы:
1. Вычисление выборочных коэффициентов корреляции.
2. Составление корреляционной таблицы.
3. Проверка статистической гипотезы значимости связи.
ОПРЕДЕЛЕНИЕ. Корреляционная зависимость между случайными величинами Х и Y называется линейной корреляцией, если обе функции регрессии f(x) и φ(x) являются линейными. В этом случае обе линии регрессии являются прямыми; они называется прямыми регрессии.
Для достаточно полного описания особенностей корреляционной зависимости между величинами недостаточно определить форму этой зависимости и в случае линейной зависимости оценить ее силу по величине коэффициента регрессии. Например, ясно, что корреляционная зависимость возраста Y учеников средней школы от года Х их обучения в школе является, как правило, более тесной, чем аналогичная зависимость возраста студентов высшего учебного заведения от года обучения, поскольку среди студентов одного и того же года обучения в вузе обычно наблюдается больший разброс в возраcте, чем у школьников одного и того же класса.
Для оценки тесноты линейных корреляционных зависимостей между величинами Х и Y по результатам выборочных наблюдений вводится понятие выборочного коэффициента линейной корреляции, определяемого формулой:
где σ X и σ Y выборочные средние квадратические отклонения величин Х и Y, которые вычисляются по формулам:
Следует отметить, что основной смысл выборочного коэффициента линейной корреляции r B состоит в том, что он представляет собой эмпирическую (т.е. найденную по результатам наблюдений над величинами Х и Y) оценку соответствующего генерального коэффициента линейной корреляции r: r=r B (9)
Принимая во внимание формулы:

видим, что выборочное уравнение линейной регрессии Y на Х имеет вид:
![]() (10)
(10)
где . То же можно сказать о выборочном уравнений линейной регрессии Х на Y:
 (11)
(11)
Основные свойства выборочного коэффициента линейной корреляции:
1. Коэффициент корреляции двух величин, не связанных линейной корреляционной зависимостью, равен нулю.
2. Коэффициент корреляции двух величин, связанных линейной корреляционной зависимостью, равен 1 в случае возрастающей зависимости и -1 в случае убывающей зависимости.
3. Абсолютная величина коэффициента корреляции двух величин, связанных линейной корреляционной зависимостью, удовлетворяет неравенству 0<|r|<1. При этом коэффициент корреляции положителен, если корреляционная зависимость возрастающая, и отрицателен, если корреляционная зависимость убывающая.
4. Чем ближе |r| к 1, тем теснее прямолинейная корреляция между величинами Y, X.
По своему характеру корреляционная связь может быть прямой и обратной, а по силе – сильной, средней, слабой. Кроме того, связь может отсутствовать или быть полной.
Сила и характер связи между параметрами
Пример 4. Изучалась зависимость между двумя величинами Y и Х. Результаты наблюдений приведены в таблице в виде двумерной выборки объема 11:
| X | |||||||||||
| Y |
Требуется:
1) Вычислить выборочный коэффициент корреляции;
2) Оценить характер и силу корреляционной зависимости;
3) Написать уравнение линейной регрессии Y на Х.
Решение. По известным формулам:

Отсюда, по (7) и (8):
Таким образом, следует сделать вывод, что рассматриваемая корреляционная зависимость между величинами Х и Y является по характеру – обратной, по силе – средней.
3) Уравнение линейной регрессии Y на Х:
Пример 5. Изучалась зависимость между качеством Y (%) и количеством Х (шт). Результаты наблюдений приведены в виде корреляционной таблицы:
| Y\X | n y | ||||
| 90 | |||||
| n x |
Требуется вычислить выборочный коэффициент линейной корреляции зависимости Y от Х.
Решение. Для упрощения вычислений перейдем к новым переменным – условным вариантам (u i , v i), воспользовавшись формулами (*) (§3) при h 1 =4, h 2 =5, x 0 =26, y 0 =80. Для удобства перепишем данную таблицу в новых обозначениях:
| u\v | -2 | -1 | n v | ||
| -2 | |||||
| -1 | |||||
| n u |
Имеем при x i =u i и y j =v j:

Таким образом:

Отсюда, ![]()
Вывод: Корреляционная зависимость между величинами Х и Y - прямая и сильная.
Множественный коэффициент корреляции характеризует тесноту линейной связи между одной переменной и совокупностью других рассматриваемых переменных.
Особое значение имеет расчет множественного коэффициента корреляции результативного признака y с факторными x1, x2,…, xm, формула для определения которого в общем случае имеет вид

где ∆r – определитель корреляционной матрицы; ∆11 – алгебраическое дополнение элемента ryy корреляционной матрицы.
Если рассматриваются лишь два факторных признака, то для вычисления множественного коэффициента корреляции можно использовать следующую формулу:

Построение множественного коэффициента корреляции целесообразно только в том случае, когда частные коэффициенты корреляции оказались значимыми, и связь между результативным признаком и факторами, включенными в модель, действительно существует.
Определение корреляции. Когда говорят о корреляции, используют термины корреляционной связи и корреляционной зависимости . Корреляционная связь обозначает согласованные изменения двух признаков и отражает тот факт, что изменчивость одного признака находится в некотором соответствии с изменчивостью другого. Прежде всего, корреляционная связь является стохастической (вероятностной) и не носит функционального характера причинно-следственных зависимостей. В корреляционных связях каждому значению одного признака может соответствовать распределение значений другого признака, но не определенное значение. Например, корреляционная связь признаков может свидетельствовать не о зависимости признаков между собой, а зависимости обоих этих признаков от какого-либо третьего или сочетания признаков, вообще не рассматриваемых в исследовании. Зависимость признаков подразумевает влияние , связь - согласованные изменения , которые могут объясняться целым комплексом причин.
Под корреляцией обычно понимается мера линейной зависимости между случайными переменными, не имеющая строгого функционального характера, при которой изменение одной из случайных величин приводит к изменению математического ожидания другой, т.е. это мера зависимости переменных, показывающая, как изменится математическое ожидание Y при изменении Х .
Числовая характеристика совместного распределения двух случайных величин, выражающая их взаимосвязь, называется коэффициентом корреляции.
Корреляционные связи различаются по форме, направлению и степени . По форме корреляционная связь может быть прямолинейной (шкала MAS Тейлора –шкала нейротизма Айзенка), или криволинейной (между уровнем эффективности решения задачи и мотивацией или тревожностью).
По направлению корреляционная связь может быть положительной (прямой) и отрицательной (обратной).
Степень, сила и теснота корреляционной связи определяется по величине коэффициента корреляции.
Сила связи не зависит от ее направленности и определяется по абсолютному значениюкоэффициента корреляции, принимая значения экстремума функции косинуса (от -1 до +1). Используется две системы классификации оценки силы корреляционной связи.
Общая классификация :
Частная классификация :
Обычно ориентируются на вторую классификацию, учитывающую объем выборки (сильная корреляция может оказаться недостоверной при малых выборках, и достоверной оказаться слабая корреляция при больших выборках, вместе с тем полагают, что сильная корреляция – это не просто корреляция высокого уровня значимости, но и с сильной теснотой связи не ниже 0,70) .
В психологических исследованиях наиболее известна линейная корреляция Пирсона . При вычислении корреляции Пирсона предполагается, что переменные измерены, как минимум, в интервальной шкале. Некоторые другие коэффициенты корреляции могут быть вычислены для менее информативных шкал. Коэффициенты корреляции изменяются в пределах от -1.00 до +1.00. Обратите внимание на крайние значения коэффициента корреляции. Значение -1.00 означает, что переменные имеют строгую отрицательную корреляцию. Значение +1.00 означает, что переменные имеют строгую положительную корреляцию. Отметим, что значение 0.00 означает отсутствие корреляции.
Наиболее часто используемый коэффициент корреляции Пирсона r называется также линейной корреляцией, т.к. измеряет степень линейных связей между переменными.
Простая линейная корреляция (Пирсона r) . Корреляция Пирсона (далее называемая просто корреляцией ) предполагает, что две рассматриваемые переменные измерены, по крайней мере, в интервальной шкале. Она определяет степень, с которой значения двух переменных "пропорциональны" друг другу. Важно, что значение коэффициента корреляции не зависит от масштаба измерения. Например, корреляция между ростом и весом будет одной и той же, независимо от того, проводились измерения в дюймах и футах или в сантиметрах и килограммах . Пропорциональность означает просто линейную зависимость . Корреляция высокая, если на графике зависимость "можно представить" прямой линией (с положительным или отрицательным углом наклона).
Проведенная прямая называется прямой регрессии или прямой, построенной методом наименьших квадратов . Последний термин связан с тем, что сумма квадратов расстояний (вычисленных по оси Y) от наблюдаемых точек до прямой является минимальной. Заметим, что использование квадратов расстояний приводит к тому, что оценки параметров прямой сильно реагируют на выбросы.
Как интерпретировать значения корреляций. Коэффициент корреляции Пирсона (r ) представляет собой меру линейной зависимости двух переменных. Если возвести его в квадрат, то полученное значение коэффициента детерминации r 2) представляет долю вариации, общую для двух переменных (иными словами, "степень" зависимости или связанности двух переменных). Чтобы оценить зависимость между переменными, нужно знать как "величину" корреляции, так и ее значимость .
Значимость корреляций . Возникает закономерный вопрос, почему более сильные зависимости между переменными являются более значимыми? Если предполагать отсутствие зависимости между соответствующими переменными в популяции, то наиболее вероятно ожидать, что в исследуемой выборке связь между этими переменными также будет отсутствовать. Таким образом, чем более сильная зависимость обнаружена в выборке, тем менее вероятно, что этой зависимости нет в популяции, из которой она извлечена. Величина зависимости и значимость тесно связаны между собой, и можно было бы попытаться вывести значимость из величины зависимости и наоборот. Однако указанная связь между зависимостью и значимостью имеет место только при фиксированном объеме выборки, поскольку при различных объемах выборки одна и та же зависимость может оказаться как высоко значимой, так и незначимой вовсе.
Уровень значимости, вычисленный для каждой корреляции, представляет собой главный источник информации о надежности корреляции. Значимость определенного коэффициента корреляции зависит от объема выборок. Критерий значимости основывается на предположении, что распределение остатков (т.е. отклонений наблюдений от регрессионной прямой) для зависимой переменной y является нормальным (с постоянной дисперсией для всех значений независимой переменной x ). Исследования методом Монте-Карло показали, что нарушение этих условий не является абсолютно критичным, если размеры выборки не слишком малы, а отклонения от нормальности не очень большие. Тем не менее, имеется несколько серьезных опасностей, о которых следует знать.
Выбросы . По определению, выбросы являются нетипичными, резко выделяющимися наблюдениями. Так как при построении прямой регрессии используется сумма квадратов расстояний наблюдаемых точек до прямой, то выбросы могут существенно повлиять на наклон прямой и, следовательно, на значение коэффициента корреляции. Поэтому единичный выброс (значение которого возводится в квадрат) способен существенно изменить наклон прямой и, следовательно, значение корреляции.
Заметим, что если размер выборки относительно мал, то добавление или исключение некоторых данных (которые, возможно, не являются "выбросами", как в предыдущем примере) способно оказать существенное влияние на прямую регрессии (и коэффициент корреляции). Это показано в следующем примере, где мы назвали исключенные точки "выбросами"; хотя, возможно, они являются не выбросами, а экстремальными значениями.
Обычно считается, что выбросы представляют собой случайную ошибку, которую следует контролировать. К сожалению, не существует общепринятого метода автоматического удаления выбросов. Чтобы не быть введенными в заблуждение полученными значениями, необходимо проверить на диаграмме рассеяния каждый важный случай значимой корреляции. Очевидно, выбросы могут не только искусственно увеличить значение коэффициента корреляции, но также реально уменьшить существующую корреляцию.
Количественный подход к выбросам. Некоторые исследователи применяют численные методы удаления выбросов. Например, исключаются значения, которые выходят за границы ±2 стандартных отклонений (и даже ±1.5 стандартных отклонений) вокруг выборочного среднего. В ряде случаев такая "чистка" данных абсолютно необходима. Например, при изучении реакции в когнитивной психологии, даже если почти все значения экспериментальных данных лежат в диапазоне 300-700 миллисекунд , то несколько "странных времен реакции" 10-15 секунд совершенно меняют общую картину. К сожалению, в общем случае, определение выбросов субъективно, и решение должно приниматься индивидуально в каждом эксперименте (с учетом особенностей эксперимента или "сложившейся практики" в данной области). Следует заметить, что в некоторых случаях относительная частота выбросов к численности групп может быть исследована и разумно проинтерпретирована с точки зрения самой организации эксперимента.
Корреляции в неоднородных группах. Отсутствие однородности в выборке также является фактором, смещающим (в ту или иную сторону) выборочную корреляцию. Представьте ситуацию, когда коэффициент корреляции вычислен по данным, которые поступили из двух различных экспериментальных групп, что, однако, было проигнорировано при вычислениях. Далее, пусть действия экспериментатора в одной из групп увеличивают значения обеих коррелированных величин, и, таким образом, данные каждой группы сильно различаются на диаграмме рассеяния (как показано ниже на графике).
В подобных ситуациях высокая корреляция может быть следствием разбиения данных на две группы, а вовсе не отражать "истинную" зависимость между двумя переменными, которая может практически отсутствовать (это можно заметить, взглянув на каждую группу отдельно, см. следующий график).
Если вы допускаете такое явление и знаете, как определить "подмножества" данных, попытайтесь вычислить корреляции отдельно для каждого множества. Если вам неясно, как определить подмножества, попытайтесь применить многомерные методы разведочного анализа.
Нелинейные зависимости между переменными. Другим возможным источником трудностей, связанным с линейной корреляцией Пирсона r , является форма зависимости. Корреляция Пирсона r хорошо подходит для описания линейной зависимости. Отклонения от линейности увеличивают общую сумму квадратов расстояний от регрессионной прямой, даже если она представляет "истинные" и очень тесные связи между переменными. Итак, еще одной причиной, вызывающей необходимость рассмотрения диаграммы рассеяния для каждого коэффициента корреляции, является нелинейность. Например, следующий график показывает сильную корреляцию между двумя переменными, которую невозможно хорошо описать с помощью линейной функции.
Измерение нелинейных зависимостей. Что делать, если корреляция сильная, однако зависимость явно нелинейная? К сожалению, не существует простого ответа на данный вопрос, так как не имеется естественного обобщения коэффициента корреляции Пирсона r на случай нелинейных зависимостей. Однако, если кривая монотонна (монотонно возрастает или, напротив, монотонно убывает), то можно преобразовать одну или обе переменные, чтобы сделать зависимость линейной, а затем уже вычислить корреляцию между преобразованными величинами. Для этого часто используется логарифмическое преобразование. Другой подход состоит в использовании непараметрической корреляции (например, корреляции Спирмена ). Иногда этот метод приводит к успеху, хотя непараметрические корреляции чувствительны только к упорядоченным значениям переменных, например, по определению, они пренебрегают монотонными преобразованиями данных. К сожалению, два самых точных метода исследования нелинейных зависимостей непросты и требуют хорошего навыка "экспериментирования" с данными. Эти методы состоят в следующем:
Нужно попытаться найти функцию, которая наилучшим способом описывает данные. После того, как вы определили функцию, можно проверить ее "степень согласия" с данными.
Вы можете иметь дело с данными, разбитыми некоторой переменной на группы (например, на 4 или 5 групп). Определите эту переменную как группирующую переменную, а затем примените дисперсионный анализ.
Разведочный анализ корреляционных матриц. Во многих исследованиях первый шаг анализа состоит в вычислении корреляционной матрицы всех переменных и проверке значимых (ожидаемых и неожиданных) корреляций. После того как это сделано, следует понять общую природу обнаруженной статистической значимости. Иными словами, понять, почему одни коэффициенты корреляции значимы, а другие нет. Однако следует иметь в виду, если используется несколько критериев, значимые результаты могут появляться "удивительно часто", и это будет происходить чисто случайным образом. Например, коэффициент, значимый на уровне.05, будет встречаться чисто случайно один раз в каждом из 20 подвергнутых исследованию коэффициентов. Нет способа автоматически выделить "истинную" корреляцию. Поэтому следует подходить с осторожностью ко всем не предсказанным или заранее не запланированным результатам и попытаться соотнести их с другими (надежными) результатами. В конечном счете, самый убедительный способ проверки состоит в проведении повторного экспериментального исследования. Такое положение является общим для всех методов анализа, использующих "множественные сравнения и статистическую значимость".
Построчное удаление пропущенных данных в сравнении с попарным удалением. Принятый по умолчанию способ удаления пропущенных данных при вычислении корреляционной матрицы - состоит в построчном удалении наблюдений с пропусками (удаляется вся строка, в которой имеется хотя бы одно пропущенное значение). Этот способ приводит к "правильной" корреляционной матрице в том смысле, что все коэффициенты вычислены по одному и тому же множеству наблюдений. Однако если пропущенные значения распределены случайным образом в переменных, то данный метод может привести к тому, что в рассматриваемом множестве данных не останется ни одного неисключенного наблюдения (в каждой строке наблюдений встретится, по крайней мере, одно пропущенное значение). Чтобы избежать подобной ситуации, используют другой способ, называемый попарным удалением . В этом способе учитываются только пропуски в каждой выбранной паре переменных и игнорируются пропуски в других переменных. Корреляция между парой переменных вычисляется по наблюдениям, где нет пропусков. Во многих ситуациях, особенно когда число пропусков относительно мало, скажем 10%, и пропуски распределены достаточно хаотично, этот метод не приводит к серьезным ошибкам. Однако, иногда это не так.
Например, в систематическом смещении (сдвиге) оценки может "скрываться" систематическое расположение пропусков, являющееся причиной различия коэффициентов корреляции, построенных по разным подмножествам. Другая проблема связанная с корреляционной матрицей, вычисленной при попарном удалении пропусков, возникает при использовании этой матрицы в других видах анализа (например, Множественная регрессия , Факторный анализ или Кластерный анализ ). В них предполагается, что используется "правильная" корреляционная матрица с определенным уровнем состоятельности и "соответствия" различных коэффициентов. Использование матрицы с "плохими" (смещенными) оценками приводит к тому, что программа либо не в состоянии анализировать такую матрицу, либо результаты будут ошибочными. Поэтому, если применяется попарный метод исключения пропущенных данных, необходимо проверить, имеются или нет систематические закономерности в распределении пропусков.
Как определить смещения, вызванные попарным удалением пропущенных данных. Если попарное исключение пропущенных данных не приводит к какому-либо систематическому сдвигу в оценках, то все эти статистики будут похожи на аналогичные статистики, вычисленные при построчном способе удаления пропусков. Если наблюдается значительное различие, то есть основание предполагать наличие сдвига в оценках. Например, если среднее (или стандартное отклонение) значений переменной A, которое использовалось при вычислении ее корреляции с переменной B, много меньше среднего (или стандартного отклонения) тех же значений переменной A, которые использовались при вычислении ее корреляции с переменной C, то имеются все основания ожидать, что эти две корреляции (A-B и A-C) основаны на разных подмножествах данных, и, таким образом, в оценках корреляций имеется сдвиг, вызванный неслучайным расположением пропусков в значениях переменных.
Попарное удаление пропущенных данных в сравнении с подстановкой среднего значения. Другим общим методом, позволяющим избежать потери наблюдений при построчном способе удаления наблюдений с пропусками, является замена средним (для каждой переменной пропущенные значения заменяются средним значением этой переменной). Подстановка среднего вместо пропусков имеет свои преимущества и недостатки в сравнении с попарным способом удаления пропусков. Основное преимущество в том, что он дает состоятельные оценки, однако имеет следующие недостатки:
Подстановка среднегоискусственно уменьшает разброс данных, иными словами, чем больше пропусков, тем больше данных, совпадающих со средним значением, искусственно добавленным в данные.
Так как пропущенные данные заменяются искусственно созданными "средними", то корреляции могут сильно уменьшиться.
Ложные корреляции . Основываясь на коэффициентах корреляции, вы не можете строго доказать причинной зависимости между переменными, однако можете определить ложные корреляции, т.е. корреляции, которые обусловлены влияниями "других", остающихся вне вашего поля зрения переменных. Лучше всего понять ложные корреляции на простом примере. Известно, что существует корреляция между ущербом, причиненным пожаром, и числом пожарных, тушивших пожар. Однако эта корреляция ничего не говорит о том, насколько уменьшатся потери, если будет вызвано меньше число пожарных. Причина в том, что имеется третья переменная (начальный размер пожара), которая влияет как на причиненный ущерб, так и на число вызванных пожарных. Если вы будете "контролировать" эту переменную (например, рассматривать только пожары определенной величины), то исходная корреляция (между ущербом и числом пожарных) либо исчезнет, либо, возможно, даже изменит свой знак. Основная проблема ложной корреляции состоит в том, что вы не знаете, кто является ее агентом. Тем не менее, если вы знаете, где искать, то можно воспользоваться частные корреляции, чтобы контролировать (частично исключенное ) влияние определенных переменных.
Являются ли коэффициенты корреляции "аддитивными"? Нет, не являются. Например, усредненный коэффициент корреляции, вычисленный по нескольким выборкам, не совпадает со "средней корреляцией" во всех этих выборках. Причина в том, что коэффициент корреляции не является линейной функцией величины зависимости между переменными. Коэффициенты корреляции не могут быть просто усреднены. Если вас интересует средний коэффициент корреляции, следует преобразовать коэффициенты корреляции в такую меру зависимости, которая будет аддитивной. Например, до того, как усреднить коэффициенты корреляции, их можно возвести в квадрат, получить коэффициенты детерминации , которые уже будут аддитивными, или преобразовать корреляции в z значения Фишера , которые также аддитивны.
Как определить, являются ли два коэффициента корреляции значимо различными . Имеется критерий, позволяющий оценить значимость различия двух коэффициентов корреляциями. Результат применения критерия зависит не только от величины разности этих коэффициентов, но и от объема выборок и величины самих этих коэффициентов. В соответствии с ранее обсуждаемыми принципами, чем больше объем выборки, тем меньший эффект мы можем значимо обнаружить. Вообще говоря, в соответствии с общим принципом, надежность коэффициента корреляции увеличивается с увеличением его абсолютного значения, относительно малые различия между большими коэффициентами могут быть значимыми.
Линейный коэффициент корреляции
Более совершенным показателем степени тесноты связи является линейный коэффициент корреляции (r ).
При расчете этого показателя учитываются не только знаки отклонений индивидуальных значений признака от средней, но и сама величина таких отклонений, т.е. соответственно для факторного и результативного признаков, величины и . Однако непосредственно сопоставлять между собой полученные абсолютные величины нельзя, так как сами признаки могут быть выражены в разных единицах (как это имеет место в представленном примере), а при наличии одних и тех же единиц измерения средние могут быть различны по величине. В этой связи сравнению могут подлежать отклонения, выраженные в относительных величинах, т.е. в долях среднего квадратического отклонения (их называют нормированными отклонениями). Так, для факторного признака будем иметь совокупность величин , а для результативного .
Полученные нормированные отклонения можно сравнивать между собой. Для того чтобы на основе сопоставления рассчитанных нормированных отклонений получить обобщающую характеристику степени тесноты связи между признаками для всей совокупности, рассчитывают среднее произведение нормированных отклонений. Полученная таким образом средняя и будет являться линейным коэффициентом корреляции r .
 (1.2)
(1.2)
или поскольку s x и s y для данных рядов являются постоянными и могут быть вынесены за скобку, то формула линейного коэффициента корреляции приобретает следующий вид:
 (1.3)
(1.3)
Линейный коэффициент корреляции может принимать любые значения в пределах от –1 до +1. Чем ближе коэффициент корреляции по абсолютной величине к 1, тем теснее связь между признаками. Знак при линейном коэффициенте корреляции указывает на направление связи: прямой зависимости соответствует знак плюс, а обратный зависимости – знак минус.
Если с увеличением значений факторного признака х , результативный признак у имеет тенденцию к увеличению, то величина коэффициента корреляции будет находиться между 0 и 1. Если же с увеличением значений х результативный признак у имеет тенденцию к снижению, коэффициент корреляции может принимать значения в интервале от 0 до –1.
Полученная величина линейного коэффициента корреляции, как и найденный выше коэффициент Фехнера, свидетельствует о возможном наличии достаточно тесной прямой зависимости между затратами на рекламу и количеством туристов, воспользовавшихся услугами фирмы.
Квадрат коэффициента корреляции (r 2) носит название коэффициента детерминации . Для рассматриваемого примера его величина равна 0,6569, а это означает, что 65,69% вариации числа клиентов, воспользовавшихся услугами фирмы, объясняется вариацией затрат фирм на рекламу своих услуг.
Здесь еще раз следует напомнить, что сама по себе величина коэффициента корреляции не является доказательством наличия причинно-следственной связи между исследуемыми признаками, а является оценкой степени взаимной согласованности в изменениях признаков. Установлению причинно-следственной зависимости предшествует анализ качественной природы явлений. Но есть и еще одно обстоятельство, объясняющее формулировку выводов о возможном наличии связи по величине коэффициента корреляции.
Связано это с тем, что оценка степени тесноты связи с помощью коэффициента корреляции производится, как правило, на основе более или менее ограниченной информации об изучаемом явлении. Возникает вопрос, насколько правомерно наше заключение по выборочным данным в отношении действительного наличия корреляционной связи в той генеральной совокупности, из которой была произведена выборка?
КОРРЕЛЯЦИОННО-РЕГРЕССИОННЫЙ АНАЛИЗ В
ЭКОНОМИЧЕСКИХ РАСЧЕТАХ
Основные понятия в корреляционном и регрессионном анализе
В математике существуют два понятия, отражающие причинно-следственные связи между признаками: функциональная и корреляционная зависимость.
Под функциональной зависимостью понимается такая связь между величинами, когда значение зависимой величины – функции – полностью определяется значениями зависимых переменных.
Корреляционная зависимость имеет место, когда каждому значекнию одной (результативной) величины соответствует множество случайных значений другой, возникающей с определенной вероятностью.
При изучении экономических явлений мы имеем дело не с функциональной, а с корреляционной зависимостью. С помощью корреляционного и регрессионного анализа можно рассчитать коэффициенты корреляции , которые оценивают силу связи между отдельными показателями, подобрать
уравнение регрессии , которое определяет форму этой связи, и установить достоверность существования этой связи.
Процесс корреляционного и регрессионного анализа экономических процессов состоит из следующих этапов:
Предварительная обработка статистических данных и выбор основных факторных признаков, влияющих на результативный показатель;
Оценка тесноты связи и выявление формы существующей связи между результативным и факторными признаками;
Разработка модели (многофакторной) изучаемого явления и ее анализ;
Применение полученных результатов проведенного анализа для принятия управленческих решений.
Перед корреляцией стоят две основные задачи. Первая заключается в выявлении, как изменяется в среднем результативный признак в связи с изменением факторного. Эта задача решается нахождением уравненимя связи. Вторая задача определяет степень влияния искажающих факторов. Эту задачу решают путем изучения показателей тесноты связи. Такими показателями являются коэффициенты корреляции и корреляционное отношение.
2. Результативный и факторный признаки . При изучении влияния одних признаков явлений на другие из цепи признаков, характеризующих данное явление, выделяются два - признака-факторный (влияющий на результат) и результативный. Необходимо установить, какой из признаков является факторным и какой результативным. В этом помогает прежде всего логический анализ.
Пример . Себестоимость промышленной продукции отдельного предприятия зависит от многих факторов, в том числе от объема продукции на данном предприятии. Себестоимость продукции выступает в этом случае как результативный признак, а объем продукции - как факториальный.
Другой пример. Чтобы судить о преимуществах крупных предприятий перед мелкими, можно рассмотреть, как увеличивается производительность труда рабочих крупных предприятий, и выявить зависимость производительности труда от увеличения размеров предприятия.
3. Понятие об уравнение связи. Уравнение этой функции будет уравнением связи между результативным и факториальным признаками.
Уравнение связи находится с помощью способа наименьших квадратов, который требует, чтобы сумма квадратов отклонений эмпирических значений от значений, получаемых на основании уравнения связи, была минимальной.
Применение способа наименьших квадратов позволяет находить параметры уравнения связи при помощи решения системы так называемых нормальных уравнений, различных для связи каждого вида.
Чтобы отметить, что зависимость между двумя признаками выражается и среднем, значения результативного признака, найденные по уравнению связи, обозначаются Ух.
Зная уравнение связи, можно вычислить заранее среднее значение результативного признака, когда значение. факториального признака известно. Таким образом, уравнение связи является методом обобщения наблюдаемых статистических связей, методом их изучения.
Применение той или иной функции в качестве уравнения связи разграничивает связи по их форме: линейную связь и криволинейную связь (параболическую, гиперболическую и др.).
Рассмотрим уравнения связи для зависимостей от одного признака при разных формах связи, (линейной, криволинейной параболической, гиперболической) и для множественной связи.
4. Линейная зависимость между признаками . Уравнение связи как уравнение прямой Ух==ао+а1х применяется в случае равномерного нарастания результативного признака с увеличением признака факториального. Такая зависимость будет зависимостью линейной (прямолинейной).
Параметры уравнения прямой линии ао и а1 находятся путем решения системы нормальных уравнений, получаемых по способу наименьших квадратов:
Примером расчета параметров уравнения и средних значений результативного признака Ух может служить следующая таблица, являющаяся результатом группировки по факториальному признаку и подсчета средних по результативному признаку.
Группировка предприятий по стоимости основных средств и подсчет сумм необходимы для уравнения связи.
Из таблицы находим: n==6; =18; =39,0; =71,5
132.0. Строим систему двух уравнений с двумя неизвестными:

Поделив каждый член в обоих уравнениях на коэффициенты при aо получим:

Вычтем из второго уравнения первое: 0,97а1=0,83; а1==0,86. Подставив значения а1 в первое уравнение aо+3*0,86 =6,5, найдем ао=6,5-2,58=+3,92.
Уравнение связи примет вид: yx=3,92+0,86х. Подставив в это уравнение соответствующие х, получим значения результативного признака, отражающие среднюю зависимость у от х в виде корреляционной зависимости.
Заметим, что суммы, исчисленные по уравнению и фактические, равны между собой. Изображение фактических и вычисленных значений на рис. 4 показывает, что уравнение связи отображает наблюденную зависимость в среднем.
5. Параболическая зависимость между признаками . Параболическая зависимость, выражаемая уравнением параболы 2-го порядка уx =ао+a1x+a2x 2 , имеет место при ускоренном возрастании или убывании результативного признака в сочетании с равномерным возрастанием факториального признака.
Параметры уравнения параболы aо; а1; а2, вычисляются путем решения системы 3 нормальных уравнений:

Возьмем для примера зависимость месячного выпуска продукции (у) от величины стоимости основных средств (х). Оба показателя округлены до миллионов рублей. Расчеты необходимых сумм приведем в табл. 5.
По данным таблицы составляем систему уравнений:

6. Уравнение гиперболы. Обратная связь указывает на убывание результативного признака при возрастании факториального. Такова линейная связь при отрицательном значении а1. В ряде других случаев обратная связь может быть выражена уравнением гиперболы
![]()
Параметры уравнения гиперболы ао и а1 находятся из системы нормальных уравнений:

7. Корреляционная таблица. При большом объеме наблюдений, когда число взаимосвязанных пар велико, парные данные легко могут быть расположёны в корреляционной таблице, являющейся наиболее удобной формой представления значительного количества пар чисел.
В корреляционной таблице один признак располагается в строках, а другой - в колонках таблицы. Число, расположенное в клетке на пересечении графы и колонки, показывает, как часто встречается данное значение результативного признака в сочетании с данным значением факториального признака.
Для простоты расчета возьмем небольшое число наблюдений на 20 предприятиях за средней месячной выработкой продукции на одного рабочего (тыс. руб.-у) и за стоимостью основных производственных средств (млн. руб.-.х).
В обычной парной таблице эти сведения располагаются так:

Итоги строк у показывают частоту признака nу, итоги граф х - частоту признака nx. Числа, стоящие в клетках корреляционной таблицы, являются частотами, относящимися к обоим признакам и обозначаются, nxy.
Корреляционная таблица даже при поверхностном знакомстве дает общее представление о прямой и обратной связи. Если частоты расположены по диагонали вниз направо, то связь между признаками прямая (при увеличивающихся значениях признака в строках и графах). Если же частоты расположены по диагонали вверх направо, то связь обратная.
8. Корреляционное отношение. Если произведено измерение явления по двум признакам, то имеется возможность находить меры рассеяния (главным образом дисперсию) по результативному признаку для одних и тех же значений факториального признака.
Дана, например, корреляционная таблица двух взаимозависимых рядов, в которых для простоты имеется лишь три.значения факториального признака количества внесенных удобрений (х), а результативный признак-урожайность (у)-значительно колеблется. Таблица 16

Каждая группа участков с разной урожайностью имела разное количество внесенных удобрений. Так, когда вносилось удобрений по 20 г/ урожайность" на разных участках была равной: на одном участке она составила 0,8 т, на двух участках- 0,9 т, на трех- 1,0 т и на одном - 1,1 т. Найдем среднюю урожайность и дисперсию по урожайности для этой группы участков.

Для группы участков с количеством внесенных удобрений 30,0 г средняя урожайность составит:

Вычислим аналогичные характеристики для группы участков. получивших удобрений по 40 т:

Из этих данных можно определить также средний урожай всех 20 участков, независимо от количества внесенных удобрений, т. е. общую среднюю:

и меру колеблемости (дисперсию) средней урожайности групп около общей средней. Эту дисперсию называют межгрупповой ^дисперсией и обозначают б 2
где уi-средние урожайности по группам участков, отличающихся количеством внесенных удобрений; m1,m2,m3,-численности групп. Межгрупповая дисперсия для данного примера составит:

Межгрупповая дисперсия показывает рассеяние, возникающее за счет факториального признака. В данном примере У= == 0,01&247 является показателем рассеяния урожайности, возникшего за счет разности в количестве внесенных удобрений.
Однако, кроме межгрупповой дисперсии, можно вычислить и дисперсию как показатель рассеяния за счет остальных факторов (если называть так все прочие факторы, кроме удобрений). Этот показатель явится средней (взвешенной) величиной из показателей рассеяния (дисперсий) по группам участков

Это практически означает, что можно получить общую меру рассеяния (дисперсию) для всех 20 участков, если имеются сведения о средних и дисперсиях по группам участков, отличающихся количеством внесенных удобрений. Следовательно, общая дисперсия по урожайности для 20 участков составит;
Формулы для исчисления межгрупповой и средней из групповых дисперсий можно сокращенно записать так:

Расчет общей дисперсии, внутригрупповой и межгрупповой дисперсии позволяет делать некоторые выводы о мере влияния факториального признака на колеблемость признака результативного. Эта мера влияния находится при помощи корреляционного отношения:


Значит, колеблемость по урожайности участков на 78% зависит от колеблемости количества внесенных удобрений.
Линейный коэффициент корреляции
При изучении тесноты связи между двумя взаимозависимыми рядами применяется линейный коэффициент корреляции, который показывает, существует ли и насколько велика связь между этими рядами. Он может принимать значения в пределах от –1 до +1.
10.Совокупный коэффициент корреляции : ,
,
где r – линейные коэффициенты корреляции, а подстрочные знаки показывают, между какими признаками они исчисляются.