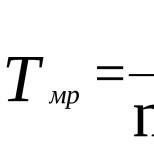Пример расчета гиперболического уравнения регрессии. Методы многомерного анализа. Показательное уравнение регрессии
Уравнение регрессии
Уравнение регрессии - это математическая формула, определяющая, каким будет среднее значение у при том или ином значении х, если все остальные факторы, влияющие на у, не учитывать, т.е. абстрагироваться от них.
Найти в каждом конкретном случае тип функции, с помощью которой можно наиболее точно отразить зависимость между х и у, - первая задача регрессионного анализа. Виды уравнений:
1) линейная зависимость ;
2) парабола ![]() ;
;
3) гипербола ;
4) показательная функция ;
5) степенная функция и т.д.
Главным основанием для выбора типа функции должен быть содержательный анализ природы изучаемого явления. Полезно отразить зависимость графически.
Метод наименьших квадратов
Далее необходимо определить параметры уравнения регрессии а 0 и а 1 , (для параболы еще и а 2 ). Для этого используют метод наименьших квадратов. В его основу положена идея минимизации суммы квадратов отклонений фактических значений у от их выравненных (теоретических) значений, т.е.
где у i - фактические значения результативного признака;
y i (x i) - значения у, найденные по уравнению регрессии.
Если регрессия линейная , то
Рассматривая сумму в качестве функции параметров а 0 и а 1 , определяют частные производные по а 0 и а 1 и приравнивают их к нулю, поскольку в точке экстремума производная функции равна нулю:
Система уравнений для разных типов зависимости между признаками
Если связь между признаками линейная, то система уравнений для нахождения параметров уравнения регрессии примет вид:

После решения системы относительно а 1 и а 1 составляют уравнение регрессии .
Если связь между признаками у их описывается уравнением параболы ![]() , то система нормальных уравнений примет вид:
, то система нормальных уравнений примет вид:
Экономический смысл параметров уравнения линейной регрессии
В уравнении линейной регрессии параметр а 0 определяет среднее значение y которое складывается под влиянием всех факторов, кроме х .
Параметр а 1 называется коэффициентом регрессии, он определяет, на сколько в среднем изменится у при изменении факторного признака на единицу. Чем больше величина а 1 , тем значительнее влияние данного факторного признака на моделируемый результативный. Знак коэффициента регрессии говорит о характере влияния фактора на результативный признак.
Коэффициент эластичности показывает, на сколько процентов изменится результативный признаку при изменении факторного признака на 1%. Общая формула для расчета коэффициента эластичности выглядит следующим образом:
![]() ,
,
где у"(х) - первая производная уравнения регрессии у(х) по х .
При различных значениях факторного признака х коэффициент эластичности принимает различные значения.
Для линейного уравнения регрессии коэффициент эластичности примет вид:
Для параболической связи коэффициент эластичности равен:
![]() .
.
Для гиперболической связи коэффициент эластичности равен:
3. Корреляционный анализ. Показатели тесноты связи между признаками
В случае линейной зависимости между признаками для оценки тесноты связи применяют линейный коэффициент корреляции :
Линейный коэффициент корреляции изменяется в пределах от -1 до +1. Если |r| <0,3, то связь слабая. Если 0,3 <|r| < 0,7, то связь средняя. Если 0,7 < |r| < 0,9, то связь выше средней или тесная. Если |r| > 0,9, то связь сильная или весьма тесная. Если , то это дает основание говорить об отсутствии линейной связи между х и у.
Экспоненциальная регрессия имеет вид
ŷ = е aх + b (или ŷ = ba х ); (24)
степенная регрессия имеет вид
ŷ = bх а ; (25)
Для нахождения коэффициентов а иb предварительно проводят процедуру линеаризации выражений (24) и (25):
lnŷ =lnb+ x lnа, (26)
lnŷ =lnb +а lnx , (27)
а затем уже строят линейную регрессию между lnŷ и х для экспоненциальной регрессии, и между lnŷ и lnх для степенной регрессии.
Наибольшее распространение степенной функции в эконометрике связано с тем, что параметр а имеет четкое экономическое истолкование, – он является коэффициентом эластичности. Это значит, что коэффициент b показывает, на сколько % в среднем изменится результат, если фактор изменится на 1%.
Для вычисления параметров экспоненциальной регрессии (24) на компьютере используется встроенная статистическая функция ЛГРФПРИБЛ . Порядок вычисления аналогичен применению функции ЛИНЕЙН .
Для вычисления параметров степенной регрессии после преобразования исходных данных в соответствие с (27), можно воспользоваться функцией ЛИНЕЙН.
Для получения графиков однофакторных регрессий можно применить Мастер диаграмм , строя предварительно непрерывный или точечный график исходных данных (диаграмму рассеяния), а затем использовать режим Добавить линию тренда , причем в этом режиме Excel предоставляет возможность выбора шести функций – линейной, логарифмической, полиномиальной, степенной, экспоненциальной и скользящей средней. После выбора функции в режиме Параметры задайте флажок Показывать уравнение на диаграмме и Поместить на диаграмму величину достоверности аппроксимации( R ^2) .
4. Временные ряды.
4.1. Характеристики временных рядов. Выявление тренда в динамических рядах экономических показателей.
Методы математической статистики широко применяются для анализа экономических временных рядов .
В общем случае временной ряд содержит детерминированную и случайную составляющие:
у t =f(t,х t)+ t , t=1,…,Т,
гдеу t – значения временного ряда; f(t,х t) – детерминированная составляющая; х t – значения факторов, влияющих на детерминированную составляющую в момент t; t – случайная составляющая; Т – длина ряда.
Получив оценки детерминированной и случайной составляющих, решают задачи прогноза будущих значений, как самого временного ряда, так и его составляющих.
Если детерминированная составляющая зависит только от времени и линейна относительно своих параметров, то задача сводится к задаче множественной линейной регрессии, рассмотренной выше.
Действительно, в этом случае
у t = 0 + 1 1 (t) + 2 2 (t) +…+ m m (t)+ t , t=1,…,Т. (28)
В частном случае,
у t = 0 + 1 t 1 + 2 t 2 +…+ m t m + t , t=1,…,Т. (29)
Детерминированная составляющая в свою очередь представляется тремя составляющими.
Долговременная эволюторно изменяющаяся составляющая является результатом действия факторов, приводящих к постепенному изменению экономического показателя. Так, в результате научно-технического прогресса, совершенствования системы управления производством показатели эффективности производства растут, а удельные расходы на единицу полезного эффекта снижаются.
Долговременная циклическая составляющая проявляется на протяжении длительного времени в результате действия факторов, обладающих большим последействием или циклически изменяющихся во времени. Например, кризисы перепроизводства или периодичность солнечной активности, влияющая на урожайность.
Сезонная циклическая составляющая легко просматривается в колебаниях продуктивности сельскохозяйственных животных, а также в колебаниях розничного товарооборота в зависимости от времени года.
Многие исследователи первую составляющую называют трендом , другие трендом называют все три составляющие.
Эволюторно изменяющуюся долговременную составляющую во многих практических случаях представляют в виде некоторой аналитической функции (см. ниже), тогда как долговременная и сезонная циклические составляющие представляются тригонометрическими трендами .
Для построения эволюторных трендов (моделирования тенденции) чаще всего применяются те же функции, которые мы рассматривали выше:
линейный тренд: ŷ t =b + at ;
гипербола: ŷ t = b+a /t ;
экспоненциальный тренд: ŷ t = е b+ a t (или ŷ t =ba t );
тренд в форме степенной функции ŷ t = b t a ;
полином порядка m: ŷ t = b + a 1 t + a 2 t 2 +…+ a m t m .
Параметры каждого из перечисленных выше трендов можно определить обычным МНК, используя в качестве независимой переменной время t. Для нелинейных трендов предварительно проводят процедуру их линеаризации.
Пример 6 . Имеются помесячные данные о темпах роста заработной платы в РФ за 10 месяцев 2004 г. в процентах к уровню декабря 2003г. (табл. 10). Требуется выбрать наилучший тип тренда и определить его параметры.
Таблица 10
Определим параметры основных видов тренда. Результаты этих расчетов представлены в табл. 11.
Таблица 11
Наилучшей является степенная форма тренда, которая в исходном виде (после потенцирования) примет следующий вид
ŷ t = е 4.39 t 0,193
или ŷ t = 80,32t 0,193 .
Наиболее простую экономическую интерпретацию имеют параметры линейного и экспоненциального трендов.
Параметры линейного тренда можно интерпретировать так:
b – начальный уровень временного ряда при t =0;
a – средний за период абсолютный прирост ряда.
Применительно к примеру 6 можно сказать, что темпы роста месячной заработной платы за 10 месяцев 2004г. изменялись от 82,66% со средним за месяц абсолютным приростом 4,72%.
Параметры экспоненциального тренда имеют следующую интерпретацию:
b – начальный уровень временного ряда при t =0;
е a – средний за период коэффициент роста ряда.
В примере 6 уравнение экспоненциального тренда в исходной форме имеет вид
ŷ t = е 4.43 е 0,045 t
или ŷ t = 83,96е 0,045 t .
Следовательно, можно сказать, что темпы роста месячной заработной платы за 10 месяцев 2004г. изменялись от 83,96% со средним за месяц темпом роста, равным е 0,045 = 1,046.
Моделирование сезонных и циклических колебаний.
Общий вид модели (аддитивной) следующий:
где Т – трендовая, S – сезонная и Е – случайная компонента.
S может моделироваться с помощью тригонометрических функций, однако можно обойтись и более простым способом, суть которого разберем на простом примере.
Пример 7. Пусть известны объемы потребления электроэнергии жителями района за четыре года (табл.12).
Таблица 12
|
№ квартала |
Потребление электроэнергии |
Итого за 4 квартала |
Скользящая средняя за 4 квартала |
Центрированная скользящая средняя |
Оценка сезонной компоненты |
Данный временной ряд содержит сезонные колебания периодичностью 4 (объемы потребления электроэнергии в осенне-зимний период выше, чем весной и летом).
Шаг 1. Проведем выравнивание исходных данных методом скользящей средней. Для этого:
а) просуммируем у t последовательно за каждые 4 квартала со сдвигом на один (гр.3 табл. 12);
б) разделив эти суммы на 4, найдем скользящие средние (гр.4 табл. 12);
в) приведем эти значения к соответствующим кварталам, для чего найдем средние значения из двух последовательных скользящих средних – центрированные скользящие средние (гр. 5 табл.12).
Шаг 2. Найдем оценки сезонной компоненты (гр.6 табл. 12). Найдем средние за каждый квартал оценки сезонной компоненты
Š 1 =(0,575+0,55+0,675)/3=0,6;
Š 2 =(–2,075 – 2,025 – 1,775)/3= –1,958;
Š 3 =(–1,25 – 1,1 – 1,475)/3= –1,275;
Š 4 =(2,55+2,7+2,875)/3=2,708.
Сумма значений сезонной компоненты по всем кварталам должна быть равна нулю, а у нас получилось 0,6 – 1,958 – 1,275 + 2,7=0,075, поэтому определяем корректирующий коэффициент k=0,075/4=0,01875. Окончательно определяем сезонную компоненту S i = Š i – k.
Таким образом, получаем
S 1 =0,581; S 2 = –1,979; S 3 = –1,294; S 4 =2,69.
Занесем полученные значения в табл.13 для соответствующих кварталов (гр.3).
Таблица 13
|
T+E= y t – S t | |||||||
Шаг 3 . Вычисляем T+E= y t – S t (гр.4 табл.13).
Шаг 4. По данным графы 4 строим линейный тренд Т=5,715 + 0,186t . Подставляя в это уравнение t =1,2,…16, находим Т (гр. 5 табл.13).
Шаг 5 . Находим теоретические значения T+S (гр. 6 табл. 13).
Шаг 6. Вычисляются ошибки модели и их квадраты (гр. 7 и 8 табл.13).
Федеральное государственное образовательное учреждение
высшего профессионального образования
«СИБИРСКИЙ ФЕДЕРАЛЬНЫЙ УНИВЕРСИТЕТ»
Институт управления бизнес-процессами и экономики
Кафедра теоретические основы экономики
Лабораторная работа № 2
по курсу эконометрика
(Вариант 6,7)
Руководитель _______________ Середа В.А.
подпись, дата
Студентка, УБ11-01 _______________ Ивкина В.А.
подпись, дата
Красноярск 2013
Введение……………………………………….…………………………………..3
1.Линейное уравнение регрессии 5
2.Показательное уравнение регрессии 7
3.Логарифмическое уравнение регрессии 9
Логарифмическое уравнение регрессии определяется по формуле: 9
Получим логарифмическое уравнение регрессии: 9
5.Поверка значимости уравнения регрессии и отдельных коэффициентов линейного уравнения 13
6.Построение интервального прогноза для значения x = xmax по уравнению линейной регрессии 17
7.Средний коэффициент эластичности 20
Цель работы: Закрепить навыки построения уравнений регрессии, графиков уравнений, вычисления оценок и построения доверительных интервалов для уравнений регрессии.
Построить уравнения регрессии, включая линейную регрессию
Вычислить индексы парной корреляции для каждого уравнения
Проверить значимость уравнений регрессии и отдельных коэффициентов линейного уравнения
Определить лучшее уравнение регрессии на основе средней ошибки аппроксимации
Построить интервальный прогноз для значения x=x max для линейного уравнения регрессии
Определить средний коэффициент эластичности
Исходные данные:
|
Области и республики |
Холодильники. Морозильники.(X ) |
Стиральные машины.(Y) |
|
Белгородская область | ||
|
Брянская область | ||
|
Владимирская область | ||
|
Воронежская область | ||
|
Ивановская область | ||
|
Калужская область | ||
|
Костромская область | ||
|
Курская область | ||
|
Липецкая область | ||
|
Московская область | ||
|
Орловская область | ||
|
Рязанская область | ||
|
Смоленская область | ||
|
Тамбовская область | ||
|
Тверская область | ||
|
Тульская область | ||
|
Ярославская область | ||
|
Республика Карелия | ||
|
Республика Коми | ||
|
Архангельская область | ||
|
Вологодская область | ||
|
Калининградская область | ||
|
Ленинградская область | ||
|
Мурманская область | ||
|
Новгородская область | ||
|
Псковская область | ||
|
Краснодарский край | ||
|
Ставропольский край | ||
|
Астраханская область | ||
|
Волгоградская область | ||
|
Ростовская область | ||
|
Республика Башкортостан | ||
|
Республика Марий Эл | ||
|
Республика Мордовия | ||
|
Республика Татарстан | ||
|
Удмуртская Республика | ||
|
Чувашская Республика | ||
|
Кировская область | ||
|
Нижегородская область | ||
|
Оренбургская область | ||
|
Пензенская область | ||
|
Пермская область | ||
|
Самарская область | ||
|
Саратовская область | ||
|
Ульяновская область |
Линейное уравнение регрессии
Формула линейного уравнения регрессии (1)
x,y – переменные,
a,b – параметры.
Система нормальных уравнений (2) в общем виде:
 (2)
(2)
n - количество наблюдений в совокупности.
Система нормальных уравнений с вычисленными коэффициентами:
![]()
Решение системы:
Построенное линейное уравнение регрессии:

Рис. 1 График линейного уравнения регрессии
Показательное уравнение регрессии
Показательное уравнение регрессии имеет следующий вид:
![]() ,
,
 ,
,
x,y – то же что и в формуле (1),
Найдем b 0 и b 1:
Полечим показательное уравнение регрессии:
Логарифмическое уравнение регрессии
Логарифмическое уравнение регрессии определяется по формуле:
x,y – то же что и в формуле (1),
b – то же что и в формуле (1),
![]() ,
,
 (8),
(8),
x,y – то же что и в формуле (1),
b – то же что и в формуле (1),
n – то же что и в формуле (2).
Найдем b 0 и b 1:
Получим логарифмическое уравнение регрессии:

Рис. 1 График логарифмического уравнения регрессии
Индекс парной корреляции для уравнений регрессии
Индекс парной корреляции исчисляется по следующей формуле:
 (9)
(9)
y – то же что и в формуле (1),
–значение у из исследуемого уравнения,
Среднее значение y.
Для оценки качества построенной модели регрессии можно использовать индекс детерминации или среднюю ошибку аппроксимации. Чем выше показатель детерминации или чем ниже ошибка аппроксимации, чем лучше модель описывает исходные данные.
Средняя ошибка аппроксимации – среднее относительное отклонение расчетных значений от фактических, рассчитывается по формуле
![]() (10)
(10)
y – то же что и в фотрмуле (1).
Индекс парной корреляции для линейного уравнения регрессии:
![]() =
0,92
=
0,92
Средняя ошибка аппроксимации для линейного уравнения регрессии:
![]() =6%
=6%
Индекс парной корреляции для логарифмического уравнения регрессии:
![]() =0,95
=0,95
Средняя ошибка аппроксимации для логарифмического уравнения регрессии:
![]() =6%
=6%
Построенные уравнения считаются удовлетворительными, так как . Коэффициент детерминации достаточно высокий, а это значит, что модель точно описывает исходные данные.
Поверка значимости уравнения регрессии и отдельных коэффициентов линейного уравнения
Оценка статистической значимости уравнения регрессии в целом осуществляется с помощью F -критерия Фишера.
Величина F факт определяется по формуле:
 (11)
(11)
Индекс детерминации,
n – то же что и в формуле (2),
m – число параметров при переменных.
Таким образом, для
F факт
=
 =2,26
=2,26
F крит =4,08, при α =0,05
F табл >
 =3,87
=3,87
F крит =4,08, при α =0,05
F табл >F факт, гипотеза H 0 не отклоняется и признается статистическая незначимость, ненадежность уравнения регрессии.
Для оценки статистической значимости коэффициентов линейной регрессии применяется t- критерий Стьюдента:
Величины t b ,факт и t a , факт определяются по формулам:
a,b – то же что и в формуле (1),
r xy - коэффициент корреляции,
m b , m a , m rxy – стандартные ошибки.
Таким образом, для
линейного уравнения регрессии:
логарифмического уравнения регрессии:
Стандартные ошибки параметров линейной регрессии и коэффициента корреляции определяются по формулам:
 (15)
(15)
 (16)
(16)
Где, y – то же что и в формуле (1),
–то же что и в формуле (9),
То же что и в формуле (9),
1. Построим уравнения степенной нелинейной регрессии вида для пар переменных y, x.
Нахождение модели парной регрессии сводится к оценке уравнения в целом и по параметрам (b0, b1). Для оценки параметров однофакторной модели используют метод наименьших квадратов (МНК). В МНК получается, что сумма квадратов отклонений фактических значений показателя у от теоретических ух минимальна
Сущность нелинейных уравнений заключается в приведении их к линейному виду и как при линейных уравнениях решается система относительно коэффициентов b0 и b1.


Рисунок 3 Линия регрессии на корреляционном поле. Ось ординат - значения y(Производительность труда), ось абсцисс -значения x (Удельный вес рабочих в составе ППП)

Рисунок 4 Линия регрессии на корреляционном поле. Ось ординат - значения y(степ.функция), ось абсцисс -значения x (Удельный вес рабочих в составе ППП)
Найдем среднюю относительную ошибку аппроксимации по формуле:

Полученное значение между 20% и 50%, что свидетельствует о существенности удовлетворительного отклонения расчетных данных от фактических, по которым построена эконометрическая модель.
Исследование статистической значимости уравнения регрессии в целом проводится с помощью F-критерия Фишера. Расчетное значение критерия находится по формуле:

Для парного уравнения p = 1.
Табличное (теоретическое) значение критерия находится по таблице критических значений распределения Фишера-Снедекора по уровню значимости по уровню значимости б и двум числам степеней свободы k1 = p = 1 и k2 = n - p - 1 = 51.
Если Fрасч то гипотеза принимается, а уравнение линейной регрессии в целом считается статистически незначимым (с вероятностью ошибки 5%).Для уравнения Fрасч = 0,01609). Неравенство выполняется. Уравнение в целом статистически незначимо. Теснота нелинейной корреляционной связи определяется с помощью корреляционных отношений (индекс корреляции). Во время учебы студенты очень часто сталкиваются с разнообразными уравнениями. Одно из них - уравнение регрессии - рассмотрено в данной статье. Такой тип уравнения применяется специально для описания характеристики связи между математическими параметрами. Данный вид равенств используют в статистике и эконометрике. В математике под регрессией подразумевается некая величина, описывающая зависимость среднего значения совокупности данных от значений другой величины. Уравнение регрессии показывает в качестве функции определенного признака среднее значение другого признака. Функция регрессии имеет вид простого уравнения у = х, в котором у выступает зависимой переменной, а х - независимой (признак-фактор). Фактически регрессия выражаться как у = f (x). В общем, выделяется два противоположных типа взаимосвязи: корреляционная и регрессионная. Первая характеризуется равноправностью условных переменных. В данном случае достоверно не известно, какая переменная зависит от другой. Если же между переменными не наблюдается равноправности и в условиях сказано, какая переменная объясняющая, а какая - зависимая, то можно говорить о наличии связи второго типа. Для того чтобы построить уравнение линейной регрессии, необходимо будет выяснить, какой тип связи наблюдается. На сегодняшний день выделяют 7 разнообразных видов регрессии: гиперболическая, линейная, множественная, нелинейная, парная, обратная, логарифмически линейная. Уравнение линейной регрессии применяют в статистике для четкого объяснения параметров уравнения. Оно выглядит как у = с+т*х+Е. Гиперболическое уравнение имеет вид правильной гиперболы у = с + т / х + Е. Логарифмически линейное уравнение выражает взаимосвязь с помощью логарифмической функции: In у = In с + т* In x + In E. Два более сложных вида регрессии - это множественная и нелинейная. Уравнение множественной регрессии выражается функцией у = f(х 1 , х 2 ...х с)+E. В данной ситуации у выступает зависимой переменной, а х - объясняющей. Переменная Е - стохастическая, она включает влияние других факторов в уравнении. Нелинейное уравнение регрессии немного противоречиво. С одной стороны, относительно учтенных показателей оно не линейное, а с другой стороны, в роли оценки показателей оно линейное. Обратная - это такой вид функции, который необходимо преобразовать в линейный вид. В самых традиционных прикладных программах она имеет вид функции у = 1/с + т*х+Е. Парное уравнение регрессии демонстрирует взаимосвязь между данными в качестве функции у = f (x) + Е. Точно так же, как и в других уравнениях, у зависит от х, а Е - стохастический параметр. Это показатель, демонстрирующий существование взаимосвязи двух явлений или процессов. Сила взаимосвязи выражается в качестве коэффициента корреляции. Его значение колеблется в рамках интервала [-1;+1]. Отрицательный показатель говорит о наличии обратной связи, положительный - о прямой. Если коэффициент принимает значение, равное 0, то взаимосвязи нет. Чем ближе значение к 1 - тем сильнее связь между параметрами, чем ближе к 0 - тем слабее. Корреляционные параметрические методы могут оценить тесноту взаимосвязи. Их используют на базе оценки распределения для изучения параметров, подчиняющихся закону нормального распределения. Параметры уравнения линейной регрессии необходимы для идентификации вида зависимости, функции регрессионного уравнения и оценивания показателей избранной формулы взаимосвязи. В качестве метода идентификации связи используется поле корреляции. Для этого все существующие данные необходимо изобразить графически. В прямоугольной двухмерной системе координат необходимо нанести все известные данные. Так образуется поле корреляции. Значение описывающего фактора отмечаются вдоль оси абсцисс, в то время как значения зависимого - вдоль оси ординат. Если между параметрами есть функциональная зависимость, они выстраиваются в форме линии. В случае если коэффициент корреляции таких данных будет менее 30 %, можно говорить о практически полном отсутствии связи. Если он находится между 30 % и 70 %, то это говорит о наличии связей средней тесноты. 100 % показатель - свидетельство функциональной связи. Нелинейное уравнение регрессии так же, как и линейное, необходимо дополнять индексом корреляции (R). Коэффициент детерминации является показателем квадрата множественной корреляции. Он говорит о тесноте взаимосвязи представленного комплекса показателей с исследуемым признаком. Он также может говорить о характере влияния параметров на результат. Уравнение множественной регрессии оценивают с помощью этого показателя. Для того чтобы вычислить показатель множественной корреляции, необходимо рассчитать его индекс. Данный метод является способом оценивания факторов регрессии. Его суть заключается в минимизировании суммы отклонений в квадрате, полученных вследствие зависимости фактора от функции. Парное линейное уравнение регрессии можно оценить с помощью такого метода. Этот тип уравнений используют в случае обнаружения между показателями парной линейной зависимости. Каждый параметр функции линейной регрессии несет определенный смысл. Парное линейное уравнение регрессии содержит два параметра: с и т. Параметр т демонстрирует среднее изменение конечного показателя функции у, при условии уменьшения (увеличения) переменной х на одну условную единицу. Если переменная х - нулевая, то функция равняется параметру с. Если же переменная х не нулевая, то фактор с не несет в себе экономический смысл. Единственное влияние на функцию оказывает знак перед фактором с. Если там минус, то можно сказать о замедленном изменении результата по сравнению с фактором. Если там плюс, то это свидетельствует об ускоренном изменении результата. Каждый параметр, изменяющий значение уравнения регрессии, можно выразить через уравнение. Например, фактор с имеет вид с = y - тх. Бывают такие условия задачи, в которых вся информация группируется по признаку x, но при этом для определенной группы указываются соответствующие средние значения зависимого показателя. В таком случае средние значения характеризуют, каким образом изменяется показатель, зависящий от х. Таким образом, сгруппированная информация помогает найти уравнение регрессии. Ее используют в качестве анализа взаимосвязей. Однако у такого метода есть свои недостатки. К сожалению, средние показатели достаточно часто подвергаются внешним колебаниям. Данные колебания не являются отображением закономерности взаимосвязи, они всего лишь маскируют ее «шум». Средние показатели демонстрируют закономерности взаимосвязи намного хуже, чем уравнение линейной регрессии. Однако их можно применять в виде базы для поиска уравнения. Перемножая численность отдельной совокупности на соответствующую среднюю можно получить сумму у в пределах группы. Далее необходимо подбить все полученные суммы и найти конечный показатель у. Чуть сложнее производить расчеты с показателем суммы ху. В том случае если интервалы малы, можно условно взять показатель х для всех единиц (в пределах группы) одинаковым. Следует перемножить его с суммой у, чтобы узнать сумму произведений x на у. Далее все суммы подбиваются вместе и получается общая сумма ху. Как рассматривалось ранее, множественная регрессия имеет функцию вида у = f (x 1 ,x 2 ,…,x m)+E. Чаще всего такое уравнение используют для решения проблемы спроса и предложения на товар, процентного дохода по выкупленным акциям, изучения причин и вида функции издержек производства. Ее также активно применяют в самых разнообразным макроэкономических исследованиях и расчетах, а вот на уровне микроэкономики такое уравнение применяют немного реже. Основной задачей множественной регрессии является построение модели данных, содержащих огромное количество информации, для того чтобы в дальнейшем определить, какое влияние имеет каждый из факторов по отдельности и в их общей совокупности на показатель, который необходимо смоделировать, и его коэффициенты. Уравнение регрессии может принимать самые разнообразные значения. При этом для оценки взаимосвязи обычно используется два типа функций: линейная и нелинейная. Линейная функция изображается в форме такой взаимосвязи: у = а 0 + a 1 х 1 + а 2 х 2 ,+ ... + a m x m . При этом а2, a m , считаются коэффициентами «чистой» регрессии. Они необходимы для характеристики среднего изменения параметра у с изменением (уменьшением или увеличением) каждого соответствующего параметра х на одну единицу, с условием стабильного значения других показателей. Нелинейные уравнения имеют, к примеру, вид степенной функции у=ах 1 b1 х 2 b2 ...x m bm . В данном случае показатели b 1 , b 2 ..... b m - называются коэффициентами эластичности, они демонстрируют, каким образом изменится результат (на сколько %) при увеличении (уменьшении) соответствующего показателя х на 1 % и при стабильном показателе остальных факторов. Для того чтобы правильно построить множественную регрессию, необходимо выяснить, на какие именно факторы следует обратить особое внимание. Необходимо иметь определенное понимание природы взаимосвязей между экономическими факторами и моделируемым. Факторы, которые необходимо будет включать, обязаны отвечать следующим признакам: Существует огромное количество методов и способов, объясняющих, каким образом можно выбрать факторы для уравнения. Однако все эти методы строятся на отборе коэффициентов с помощью показателя корреляции. Среди них выделяют: Первый метод подразумевает отсев всех коэффициентов из совокупного набора. Второй метод включает введение множества дополнительных факторов. Ну а третий - отсев факторов, которые были ранее применены для уравнения. Каждый из этих методов имеет право на существование. У них есть свои плюсы и минусы, но они все по-своему могут решить вопрос отсева ненужных показателей. Как правило, результаты, полученные каждым отдельным методом, достаточно близки. Такие способы определения факторов базируются на рассмотрении отдельных сочетаний взаимосвязанных признаков. Они включают в себя дискриминантный анализ, распознание обликов, способ главных компонент и анализ кластеров. Кроме того, существует также факторный анализ, однако он появился вследствие развития способа компонент. Все они применяются в определенных обстоятельствах, при наличии определенных условий и факторов.Определение понятия регрессии
Какие бывают типы связей между переменными
Виды регрессий

Гиперболическая, линейная и логарифмическая
Множественная и нелинейная

Обратные и парные виды регрессий

Понятие корреляции
Методы
Корреляция для множественной регрессии

Метод наименьших квадратов
Параметры уравнений

Сгруппированные данные
Множественное парное уравнение регрессии: оценка важности связи

Какие факторы необходимо учитывать при построении множественной регрессии
Методы построения
Методы многомерного анализа