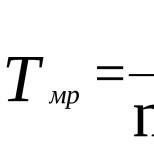Какие тесты выделяют по критерию эффективности. Тесты в процессе разработки программного обеспечения. Тестирование методом серого ящика
В. В. Одинцова
Пользуясь многочисленными психодиагностическими методиками, мы редко задумываемся о качестве этих рабочих инструментов. И напрасно. Ведь любому практикующему психологу известно, что ни одно психологическое обследование невозможно без хорошего диагностического инструментария.
При этом популярные сборники психологических тестов, широко публикуемые в последнее время, к сожалению, не могут удовлетворить требованиям настоящего профессионала, который должен быть уверен в диагностических возможностях того инструмента, который он использует в своей работе. Поэтому, проблема поиска грамотно разработанной и надежной диагностической методики остается актуальной .
Основной задачей HR-Лаборатории Human Technologies является разработка качественной продукции. Одним из условий создания такой продукции являются периодические проверки тестовых методик на предмет их соответствия ряду психометрических требований (валидности, надежности, репрезентативности, достоверности). Для этого, после набора достаточного количества протоколов проводится статистический анализ тестовых методик.
Рассмотрим психометрический анализ (общая выборка которого составила 660 человек).
Данный тест, разработанный в 90-е гг., предназначен для экспресс-диагностики уровня выраженности пяти так называемых "больших" факторов темперамента и характера и используется для исследования личности взрослых людей с целью профотбора, профконсультации, определения направлений психологической помощи, комплектования групп, самопознания и т.п.
Основой универсальности "Большой пятерки факторов" является их кросс-ситуационность: факторы глобальной функционально-деятельностной оценки человека приложимы практически к любой ситуации социального поведения и предметной деятельности, в которых обнаруживаются устойчивые различия между людьми.
Опросник включает 75 пунктов по три варианта ответа в каждом.
ШКАЛЫ теста представляют собой точное воспроизведение факторов "Большой Пятерки" в их международном варианте (за исключением пятого фактора, который в ряде западных версий B5 обозначается как "открытость новому опыту - ограниченный практицизм"):
- экстраверсия - интроверсия
- согласие - независимость
- организованность - импульсивность
- эмоциональная стабильность - тревожность
- обучаемость - инертность
1. Проверка валидности
При проверке существующих шкал традиционным способом - путем расчета корреляций между ответами на вопросы и суммарным баллом по шкале - мы выяснили, что практически все пункты значимо коррелируют со "своими" шкалами со средним коэффициентом корреляции равным 0,35.
При проверке содержательной валидности теста были проанализированы формулировки заданий теста, содержательно отражающие соответствующую предметную область (область поведения) и имеющие значимую (положительную или отрицательную) корреляцию с суммарным баллом:
| Шкала | Пример заданий теста | Коэффициент корреляции |
| ЭКСТРАВЕРСИЯ | Для меня важно высказать свое мнение окружающим | (0,31) |
| Я люблю участвовать во всевозможных конкурсах, соревнованиях и т.п. | (0,41) | |
| Мне нравится ходить в гости и знакомиться с новыми людьми | (0,5) | |
| СОГЛАСИЕ | Большинству людей нельзя доверять | (-0,23) |
| Мои интересы для меня превыше всего | (-0,22) | |
| "Кто людям помогает, тот тратит время зря, хорошими делами прославиться нельзя" | (-0,3) | |
| "Каждый - сам за себя" - вот принцип, который не подведет | (-0,4) | |
| САМОКОНТРОЛЬ | Когда я ложусь спать, то уже наверняка знаю, что буду делать завтра | (0,37) |
| Взяв книгу, я всегда ставлю ее на место | (0,35) | |
| Перед ответственными делами я всегда составляю план их выполнения | (0,37) | |
| СТАБИЛЬНОСТЬ | Я легко краснею | (-0,28) |
| Если я уловил(а) возникновение нежелательной ситуации на работе, то это всегда вызывает у меня тягостное сомнение до тех пор, пока ситуация не прояснится | (-0,3) | |
| В конце дня я обычно устаю настолько, что любая мелочь начинает выводить из себя | (-0,32) | |
| Испортить мне настроение совсем просто | (-0,42) |
Анализ приведенных формулировок говорит о достаточно высокой содержательной валидности теста.
2. Проверка надежности
Надежность теста как средства измерения определяется низкой вероятностью ошибок измерения тестовых баллов и тем, в какой мере результаты измерений воспроизводятся при многократном использовании теста по отношению к данной группе испытуемых. Чтобы оценить вклад различных источников в ошибку измерения, необходимо использовать разные способы оценки надежности. Особый интерес представляет оценка внутренней согласованности теста, она обуславливает ту часть ошибки, которая связана с отбором заданий.
Оценка внутренней согласованности теста производилась посредством расчета альфа-коэффициента Кронбаха. Данный коэффициент представляет собой оценку надежности, базирующуюся на гомогенности шкалы или сумме корреляций между ответами испытуемых на вопросы внутри одной и той же тестовой формы.
В нашем случае рассчитанный для каждой шкалы альфа-коэффициент надежности Кронбаха показал в целом вполне приличный уровень внутренней согласованности, традиционный для личностных экспресс-опросников, в которых субшкалы содержат ограниченное число пунктов (менее 20):
Напомним, что строгим психометрическим требованиям, предъявляемым к эффективно работающему личностному тесту, соответствует значение альфа-коэффициентов выше 0,8.
В нашем же случае относительно низкий уровень значения коэффициентов надежности Кронбаха можно объяснить содержательной объемностью данных шкал: на каждую шкалу приходится по 15 разноплановых вопросов, что позволяет расширить область охвата исследуемых факторов, жертвуя вместе с тем высоким уровнем внутренней согласованности.
Особенно остро это сказалось на факторных шкалах "СОГЛАСИЕ" и "ОБУЧАЕМОСТЬ", по которой альфа-коэффициент оказался ниже 0,6.
3. Проверка репрезентативности
При переходе от выборки стандартизации (рис.1 - 300 человек) к выборке популяции (рис.2 - 660 человек) проявляется устойчивость конфигурации распределения тестовых баллов, что говорит о репрезентативности тестовой методики:
Рис.1. Выборка стандартизации (300 человек)

Рис.2. Выборка популяции (660 человек)
Помимо визуальной схожести этих распределений, использованный нами статистический хи-квадрат критерий Пирсона показал следующую степень сходства распределений:
Данные значения хи-квадрата попадают в промежуток неопределенности: когда нельзя однозначно принять или однозначно отвергнуть гипотезу о согласованности распределений.
Такой результат может быть обусловлен основным свойством экспресс-теста, а именно - малым количеством вопросов, работающих на каждую шкалу. Учитывая этот факт, результаты проверки репрезентативности можно признать удовлетворительными.
4. Проверка достоверности
Так как испытуемые, проходившие тестирование на сайте, находились в ситуации клиента (были заинтересованы в достоверных результатах), то с высокой вероятностью полученные результаты можно считать достоверными.
Однако в ситуации экспертизы (когда в результатах тестирования заинтересовано третье лицо), данные могут искажаться от вмешательства сознательных фальсификаций (лжи, неискренности испытуемого) или бессознательных мотивационных факторов. Чтобы избежать этого в версию, предназначенную для подобных случаев (B5splus), была добавлена шкала лжи (в данный момент эта версия проходит апробацию на нашем сайте) .
Полученные результаты являются свидетельством высокого качества и эффективности методики, что немаловажно, ведь профессиональный уровень специалиста, зачастую, определяется тем инструментом, которым он пользуется.
Однако, следует помнить, что даже мощный современный инструмент не гарантирует полного отсутствия ошибок. Для того чтобы избежать их, мало иметь компьютер и тестовую программу к нему. Обязательно нужен еще и опытный психолог, контролирующий выполнение теста. Так что наличие тестов, прошедших серьезную психометрическую адаптацию, вовсе не отменяет профессионализма и опыта психолога, призванного проверять правдоподобность тестовых результатов с использованием параллельных источников информации (включая собственное наблюдение, беседу и т.п.).
Перевод : Ольга Алифанова
В обеспечении качества различают верификацию и валидацию. Верификация отвечает на вопрос, правильно ли мы создаем продукт, а валидация – на вопрос, а то ли мы вообще создаем, что нужно. Некоторые люди проводят водораздел между обеспечением качества и тестированием, исходя именно из этих определений.
С моей точки зрения, использование терминов "верификация" и "валидация" может привести к ложным дихотомиям. Для меня тестирование – это деятельность, связанная с дизайном , и поэтому покрывает довольно широкую область. Я верю, что тесты могут стать неким "общим языком ". Я верю, что тесты могут напрямую кодировать спецификации и требования. И я верю, что тесты – это источник знаний об области или продукте. Слишком большой упор на разницу между верификацией и валидацией – это неэффективный и не результативный способ понять, как именно тестирование дополняет обеспечение качества.
С моей точки зрения, неспособность воспринимать тестирование и обеспечение качества, как два различных, дополняющих друг друга процесса – это восприятие, которому явно не хватает некоторого изящества.
На самом деле я согласен, что различия между верификацией и валидацией вполне оправданы. В конце концов, эффективность – это способность делать что-то правильно. Результативность, с другой стороны – это способность выдавать правильный результат. Эффективность сфокусирована на процессе и нацелена на доведение его до конца, а результативность – на продукте (то есть, собственно, на результате этого процесса). Можно сказать и так: эффективность концентрируется в первую очередь на том, чтобы избежать ошибок, а результативность – на успехе вне зависимости от количества промахов, допущенных по пути.
Однако мне кажется, что есть способ различать эффективность и результативность, который куда лучше понимания разницы между верификацией и валидацией. Ведь тестирование прямо-таки требует гибкости и инноваций.
И это именно та точка, в которой возникает любопытный парадокс. Для постоянного, непрерывного поддержания эффективности вам требуется приличный уровень дисциплины и твердости. Однако именно дисциплина и устойчивость к переменам лишают процессы гибкости! Если вы делаете одно и то же одинаково раз за разом, вас никогда не осенит ничем инновационным.
Так как эффективность в данном контексте связана с верификацией, это означает, что верификация может превратиться в статическую деятельность.
Результативность, напротив, куда лучше адаптируется к переменам и требует большой гибкости. Для достижения хороших результатов нужно поощрять инновацию, потому что тогда люди будут задумываться о том, что именно они сейчас делают, и стоит ли заниматься именно этим в конкретном контексте и при воздействии конкретных факторов. Однако эта гибкость и адаптивность ведут к чересчур большому богатству выборов и потенциальной неспособности на сознательные рутинные усилия, которые можно будет воспроизвести и вне текущей ситуации.
Так как эффективность в нашем контексте увязана с валидацией, все вышесказанное означает, что валидация может стать чересчур динамичным видом деятельности.
И тут-то в игру должно вступать изящество решений, разрывающее этот порочный круг и дающее вам возможность оценить свою эффективность и результативность, смотря на нее другими глазами. Изящество решений не просто отвечает на вопросы, сделали ли мы что-то лучше, или подумали ли мы о чем-то получше, а скорее дает ответ, стали ли мы лучше понимать, что происходит, создали ли мы базу для будущей деятельности?
Изящество можно рассматривать в том числе как минимизацию сложности. В мире разработки люди часто делят сложность решений на обязательную и случайную. Следовательно, для того, чтобы решения в тестировании были изящными, они должны состоять только из "обязательной сложности" и практически не содержать случайной. Звучит, наверное, загадочно? Да, возможно, так как сколько людей – столько мнений о том, где начинается "сложность". Для меня сложность решений в тестировании возникает, когда в системе нет выборов и в наличии высокая неопределенность.
Если вы позволяете тестированию быть инновационным и гибким (то есть результативным), но при этом поддерживаете определенный уровень жесткости и дисциплины (эффективность), у вас должен быть некий свод правил насчет того, как управляться с выбором (в смысле, как предоставлять этот выбор) и неопределенностью (как ее уничтожать).
Не буду занудничать на эту тему, а просто приведу примеры того, о чем я говорю. В своих примерах я хочу попробовать заставить команды тестирования думать о своих тестах, используя термины "эффективность", "результативность" и "изящество". Начну с некоторых аксиом (не подберу другого слова) и постараюсь сделать свои примеры как можно короче и понятнее. Есть вещи, в которые должна верить вся команда – или, как минимум, действовать так, как будто она в них верит. И первая же моя аксиома утверждает то, о чем я выше говорил!
- Тестирование может выполняться эффективно, результативно и изящно.
- Тестирование требует активных, профессиональных, технических исследований.
- Цель тестирования – это внятное донесение нужной информации вовремя.
- Тестировщики в каком-то смысле – писатели и редакторы. Следовательно, этика изящества и профессиональная гордость – непременные атрибуты хорошей, мотивированной работы с должным уровнем внимания.
Вот несколько примеров, иллюстрирующих эти положения. Для начала давайте рассмотрим все эти концепции применительно к тесту.
- Эффективный тест должен концентрироваться на вводе, процессе, выводе.
- Результативный тест должен быть выразительным и демонстрировать цель теста.
- Эффективный тест должен фокусироваться на одном внятном результате конкретного действия, а не на нескольких одновременно.
- Результативный тест группирует связанные между собой наблюдения.
- Эффективный тест дает конкретный пример нужных данных.
- Результативный тест рассказывает про общие условия, под которые должны попадать тестируемые данные.
- Изящный тест описывает конкретное поведение системы и ее функциональность.
Теперь давайте применим эти концепции к тест-сьюту:
- Эффективный тест-сьют определяет, какие данные будут валидными, а какие нет.
- Эффективный тест-сьют проверяет и валидные, и невалидные данные.
- Результативный тест-сьют группирует типы данных в классы.
- Изящный тест-сьют может составляться для исследований задач бизнеса и его процессов.
И, наконец, давайте приложим эти определения к тестированию как виду деятельности:
- Эффективное тестирование использует скрипты, структурирующие исследовательский процесс.
- Результативное тестирование применяет исследовательские практики, которые привносят в скрипты вариативность.
- Изящное тестирование использует скриптованные исследовательские практики, чтобы продемонстрировать ценность приложения для потребителя путем изучения того, как оно используется.
- Эффективное тестирование использует сценарии, показывающие, как продукт реализует свое назначение.
- Результативное тестирование использует сценарии, которые демонстрируют, что должно произойти, чтобы пользовательская потребность была удовлетворена.
- Изящное тестирование описывает требования и демонстрирует возможности приложения.
Все это важно осознавать, так как то, что вы делаете и то, как именно вы это делаете – это основа того, что и как вы будете делать в будущем. Это также поддерживает групповую динамику и размышления о вышеприведенных концепциях. Вот что я имею в виду:
- Некоторые тестировщики предпочитают называть тест-кейсы "условиями теста". Некоторые – наоборот. Кто-то игнорирует оба термина. Я считаю, что результативное тестирование группирует тестовые условия и делает их вариациями тест-кейсов. Результативное тестирование использует условия теста, заданные особыми параметрами нужных данных.
- Терминология "позитивное/негативное тестирование" давно уже вышла из моды у опытных тестировщиков. Изящное тестирование концентрируется на описании валидных и невалидных условий. Это означает, что тестировщики должны эффективно и результативно тестировать, определяя все условия теста, которые могут изменяться (что приводит, в свою очередь, к группировке валидных и невалидных условий), а также убедиться, что они принимают взвешенные решения, выбирая определенные наборы данных и игнорируя остальные.
- Изящные тесты – это чемпионы ваших тестов. Если у вас есть группа тестов, проверяющих по факту схожие вещи, а ваше время ограничено – вы успеете прогнать только часть из них. В таких случаях используйте тесты, которые с большой долей вероятности вскроют целый пласт ошибок. Такие тесты могут быть крайне изящными.
- Эффективный тест должен быть ни слишком простым, ни чересчур сложным. Конечно, возможно впихнуть в один кейс целую серию проверок, но возможные побочные эффекты такого способа создания тестов могут замаскировать кучу багов. Следовательно, результативные кейсы должны включать разные точки наблюдения (или другой путь к той же самой точке наблюдения), и выполняться по отдельности.
- Некоторые техники тестирования крайне эффективны в плане выбора специфических данных и организации этих данных в комбинации или последовательности. Но изящное решение возникнет, когда тестировщики выбирают эти данные, исходя из взаимодействия разных функциональностей и потоков данных, и исследуют пути через пользовательский интерфейс с пониманием того, как живой человек будет использовать эту систему.
- Результативный кейс должен быть способен дать вам информацию. Вам нужны тесты, которые дадут ответы на вопросы, заданные вами. Цель теста – совершенно необязательно поиск бага, его цель – это сбор информации. Тест ценен не тогда, когда он может найти баг – он должен быть способен снабжать вас информацией (хотя эта информация может заключаться и в наличии бага, если с приложением что-то не так). Изящное решение всегда нацелено на получение определенной информации в ходе тестирования.
- Результативное тестирование нуждается в понимании требований и их связи с тем, как пользователи воспринимают ценность нашего продукта. Нам нужно понимать наших пользователей, а не просто читать спецификации и требования! Изящное тестирование использует эвристики для структурирования этого понимания. Оно также заставляет тестирование рассказывать захватывающие истории о действиях реальных людей.
Возможно, мне с самого начала стоило отметить, что у меня не было цели выставить себя истиной в последней инстанции в плане ответа на вопрос, какое тестирование будет эффективным, результативным и изящным. Я только хотел донести свою позицию: я считаю, что команды тестирования, которые понимают разницу между этими концепциями, способны
Каждый раз, когда мы заваливаем очередной релиз, начинается суета. Сразу появляются виноватые, и зачастую – это мы, тестировщики. Наверное это судьба – быть последним звеном в жизненном цикле программного обеспечения, поэтому даже если разработчик тратит уйму времени на написание кода, то никто даже не думает о том, что тестирование – это тоже люди, имеющие определенные возможности.
Выше головы не прыгнуть, но можно же работать по 10-12 часов. Я очень часто слышал такие фразы)))
Когда тестирование не соответствует потребностям бизнеса – то возникает вопрос, зачем вообще тестирование, если они не успевают работать в установленные сроки. Никто не думает о том, что было раньше, почему требования нормально не написали, почему не продумали архитектуру, почему код кривой. Но зато когда у вас дедлайн, а вы не успеваете завершить тестирование, то тут вас сразу начинают карать…
Но это было пару слов о нелегкой жизни тестировщика. Теперь к сути 🙂
После пару таких факапов все начинают задумываться, что не так в нашем процессе тестирования. Возможно, вы, как руководитель, вы понимаете проблемы, но как их донести до руководства? Вопрос?
Руководству нужны цифры, статистика. Простые слова – это вас послушали, покивали головой, сказали – “Давай, делай” и все. После этого все ждут от вас чуда, но даже если вы что-то предприняли и у вас не получилось, вы или Ваш руководитель опять получает по шапке.
Любое изменение должно поддерживаться руководством, а чтобы руководство его поддержало, им нужны цифры, измерения, статистика.
Много раз видел, как из таск-трекеров пытались выгружать различную статистику, говоря, что “Мы снимаем метрики из JIRA”. Но давайте разберемся, что такое метрика.
Метрика - технически или процедурно измеримая величина, характеризующая состояние объекта управления.
Вот посмотрим – наша команда находит 50 дефектов при приемочном тестировании. Это много? Или мало? Говорят ли Вам эти 50 дефектов о состоянии объекта управления, в частности, процесса тестирования?
Наверное, нет.
А если бы Вам сказали, что количество дефектов найденных на приемочном тестировании равно 80%, при том, что должно быть всего 60%. Я думаю тут сразу понятно, что дефектов много, соответственно, мягко говоря, код разработчиков полное г….. неудовлетворителен с точки зрения качества.
Кто-то может сказать, что зачем тогда тестирование? Но я скажу, что дефекты – это время тестирования, а время тестирования – это то, что напрямую влияет на наш дедлайн.
Поэтому нужны не просто метрики, нужны KPI.
KPI – метрика, которая служит индикатором состояния объекта управления. Обязательное условие – наличие целевого значения и установленные допустимые отклонения.
То есть всегда, строя систему метрик, у вас должна быть цель и допустимые отклонения.
Например, Вам необходимо (Ваша цель), чтобы 90% всех дефектов решались с первой итерации. При этом, вы понимаете, что это не всегда возможно, но даже если количество дефектов, решенных с первого раза, будет равняться 70% – это тоже хорошо.
То есть, вы поставили себе цель и допустимое отклонение. Теперь, если вы посчитаете дефекты в релизе и получите значение в 86% – то это конечно не хорошо, но и уже не провал.
Математически это будет выглядеть, как:
Почему 2 формулы? Это связано с тем, что существует понятие восходящих и нисходящих метрик, т.е. когда наше целевое значение стремится к 100% или к 0%.
Т.е. если мы говорим, к примеру, о количестве дефектов, найденных после внедрения в промышленной эксплуатации, то тут, чем меньше, тем лучше, а если мы говорим о покрытии функционала тест-кейсами, то тогда все будет наоборот.
При этом не стоит забывать о том, как рассчитывать ту или иную метрику.
Для того, чтобы получить необходимые нам проценты, штуки и т.д., нужно производить расчет каждой метрики.
Для наглядного примера я расскажу Вам о метрике “Своевременность обработки дефектов тестированием”.
Используя аналогичный подход, о котором я рассказал выше, мы также на основе целевых значений и отклонений формируем показать KPI для метрики.
Не пугайтесь, в жизни это не так сложно, как выглядит на картинке!

Что мы имеем?
Ну понятно, что номер релиза, номер инцидента….
Critical - коэф. 5,
Major - коэф. 3,
Minor - коэф. 1,5.
Далее необходимо указать SLA на время обработки дефекта. Для этого определяется целевое значение и максимально допустимое время ретестирования, аналогично тому, как я описывал это выше для расчета показателей метрик.
Для ответа на эти вопросы мы сразу перенесемся к показателю эффективности и сразу зададим вопрос. А как рассчитать показатель, если значение одного запроса может равняться “нулю”. Если один или несколько показателей будет равно нулевому значению, то итоговый показатель при этом будет очень сильно снижаться, поэтому возникает вопрос, как наш расчет сбалансировать так, чтобы нулевые значения, к примеру, запросов с коэффициентом тяжести “1” не сильно влияли на нашу итоговую оценку.
Вес - это значение, которое необходимо нам для того, чтобы сделать наименьшим влияние запросов на итоговую оценку с низким коэффициентом тяжести, и наоборот, запрос с наибольшим коэффициентом тяжести имеет серьезное влияние на оценку, при условии того, что мы просрочили сроки по данному запросу.
Для того, чтобы у вас не сложилось непонимания в расчетах, введем конкретные переменные для расчета:
х - фактические время, потраченное на ретестирование дефекта;
y - максимально допустимое отклонение;
z - коэффициент тяжести.

Или на обычно языке, это:
W = E СЛИ (x<=y,1,(x/y)^z)
Таким образом, даже, если мы вышли за установленные нами рамки по SLA, наш запрос в зависимости от тяжести не будет серьезно влиять на наш итоговый показатель.
Все как и описывал выше:
х – фактические время, потраченное на ретестирование дефекта;
y – максимально допустимое отклонение;
z – коэффициент тяжести.
h –
плановое время по SLA
Как это выразить в математической формуле я уже не знаю, поэтому буду писать программным языком с оператором ЕСЛИ.
R = ЕСЛИ(x<=h;1;ЕСЛИ(x<=y;(1/z)/(x/y);0))
В итоге мы получаем, что если мы достигли цели, то наше значение запроса равно 1, если вышли за рамки допустимого отклонения, то рейтинг равен нулевому значению и идет расчет весов.
Если наше значение находится в пределах между целевым и максимально допустимым отклонением, то в зависимости от коэффициента тяжести, наше значение варьируется в диапазоне .
Теперь приведу пару примеров того, как это будет выглядеть в нашей системе метрик.
Для каждого запроса в зависимости от их важности (коэффициент тяжести) имеется свой SLA.
Что мы тут видим.
В первом запросе мы на час всего лишь отклонились от нашего целевого значения и уже имеем рейтинг 30%, при этом во втором запросе мы тоже отклонились всего на один час, но сумма показателей уже равна не 30%, а 42,86%. То есть коэффициенты тяжести играют важную роль в формировании итогового показателя запроса.
При этом в третьем запросе мы нарушили максимально допустимое время и рейтинг равен нулевому значению, но вес запроса изменился, что позволяет нам более правильно посчитать влияние этого запроса на итоговый коэффициент.
Ну и чтобы в этом убедиться, можно просто посчитать, что среднее арифметическое показателей будет равно 43,21%, а у нас получилось 33,49%, что говорит о серьезном влиянии запросов с высокой важностью.
Давайте изменим в системе значения на 1 час.

при этом, для 5-го приоритета значение изменилось на 6%, а для третьего на 5,36%.
Опять же важность запроса влияет на его показатель.
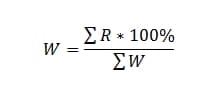
Все, мы получаем итоговый показатель метрики.
Что Важно!
Я не говорю о том, что использование системы метрик нужно делать по аналогии с моими значениями, я лишь предлагаю подход к их ведению и сбору.
В одной организации я видел, что был разработан собственный фреймворк для сбора метрик из HP ALM и JIRA. Это действительно круто. Но важно помнить, что подобный процесс ведения метрик требует серьезного соблюдения регламентных процессов.
Ну и что самое важное – только вы можете решить, как и какие метрики Вам собирать. Не нужно копировать те метрики, которые вы собрать не сможете.
Подход сложный, но действенный.
Попробуйте и возможно у вас тоже получится!
Александр Мешков – Chief Operations Officer в Перфоманс Лаб, – обладает опытом более 5 лет в области тестирования ПО, тест-менеджмента и QA-консалтинга. Эксперт ISTQB, TPI, TMMI.
Отказ от тестирования часто связан с критическим отношением к нему со стороны рекламных (особенно творческих) работников, а также с экономией денежных средств и времени. Тестирование может затормозить запуск рекламной кампании, а значит – и самого продукта. Вместе с тем очевидно, что при больших бюджетах тестирование помогает избежать многомиллионных ошибок. Оно также может быть полезным и для некрупных рекламодателей, для которых несложно подобрать простые, недорогие тесты. Как говорят классики рекламы, «тестирование может быть ограниченным или даже неудачным, но оно все равно даст что-то, от чего можно отталкиваться, чем можно руководствоваться».
Исследователи насчитывают несколько тысяч видов тестов. Не меньше существует и мнений о полезности и правильности проведения тех или иных тестов.
Один из основных вопросов оценочных иссл дований: «Что собственно тестировать?» Те же классики рекламы утверждали, что «эффект рекламы (за исключением рекламы посылторга) в основном не поддается измерению... Рекламодатели, конечно же, хотят иметь возможность учета, но рекламу часто приходится измерять методами более скромными и более неосязаемыми, чем хотелось бы. Боюсь, нам придется примириться с тем, что большая часть рекламы сможет полностью окупить себя только по прошествии длительного отрезка времени, а степень окупаемости невозможно проверить сколь-нибудь точно».
Действительно, выявить решающий фактор зависимости между самим рекламным обращением и его воздействием (или отсутствием этого воздействия) на отдельного человек весьма затруднительно. Например, в ходе одного из исследований группу, состоящую из управляющих по товару и управляющих службой рекламы фирм, руководителей рабочих групп рекламных агентств, творческих работников, специалистов по средствам рекламы и специалистов исследовательских служб, «попросили отобрать лучшие объявления из числа тех, что были уже тщательно проверены на рынке. Результат? Хотя экспертам, в общем-то, удалось установить, какие объявления должны были привлечь наибольшее число читателей, они не сумели определить, какие объявления помогли продать больше товара». Как уже говорилось ранее, кроме рекламы, слишком много других различных факторов влияет на продажи. А по утверждению авторитетнейших специалистов, «методов быстрого и несложного контроля многочисленных факторов, оказывающих влияние на сбыт, не существует».
Согласно мнению Ч. Сэндиджа, В. Фрайбургера и К.Ротцолла, «на реакцию влияет множество всевозможных “причин”, а каждая переменная раздражителя порождает множество “эффектов”. Одно и то же объявление может, к примеру, раздражать, информировать, забавлять, подкреплять уверенность, побуждать к действию, может оказаться полностью проигнорированным в момент контакта, а позднее его могут быстро забыть или частично припомнить, оно же может стать причиной перемены в отношении или осведомленности. Поэтому совершенно ясно, что, решая, какими параметрами ответной реакции воспользоваться, исследователь должен во многом руководствоваться здравым смыслом».
В связи с вышесказанным представляется очевидным, что объявление (прежде чем на него отреагируют) должно быть увидено. После контакта с рекламой человек также должен знать торговую марку или название компании, разбираться в свойствах, преимуществах и выгодах товара. У человека может появиться рациональная или эмоциональная предрасположенность к покупке определенного товара. К этому можно добавить мнение руководства одного из крупнейших мировых рекламодателей General Motors : «Эффективность будет прежде всего измеряться достоверностью, способностью использовать эмоции и убедительностью рекламы».
Тестированию можно подвергать именно определенные человеческие реакции. При этом оценке следует подвергать или одиночные параметры, или минимальный набор, так как попытки анализировать сразу слишком большое количество действующих параметров рекламы могут спутать результаты. Вместе с тем, чем больше в целом параметров будет протестировано, тем точнее будет конечный результат. «При тщательном анализе всего одного-двух периферийных аспектов эффективности рекламы результаты ее тестирования могут показаться слишком стерильными и нереальными для тех, кто должен будет пользоваться ими в процессе принятия решений. Если он некритично поставит знак равенства между степенью запоминаемости и воздействием или изменением отношения и сбытом, у него остается возможность положиться на веру, не дающую никаких гарантий».
Итак, для проверки эффективности завершенной или почти завершенной рекламы проводятся различные оценочные исследования или тесты. Они позволяют сэкономить средства за счет корректировки рекламы до того, как будут профинансированы средства ее распространения. Таким образом тестирование помогает избежать многомиллионных ошибок. Также оценочные исследования могут быть полезны и после размещения рекламы, например при оценке процессов влияния рекламы на текущие продажи.
Однако с точки зрения практиков не все исследования и не всегда имеют ценность. Иногда они могут не только помогать, но и вредить работе. Интуиция практиков может оказаться более точным инструментом, чем научные изыскания. Тесты и их результаты – это не сами решения, они лишь предоставляют практикам информацию, использование которой, совместно с эмпирическим опытом рекламного работника, дает возможность принимать взвешенные решения.
В настоящей главе были рассмотрены различные виды тестов, применяемы в рекламе, различные методы тестирования, критерии тестирования и этапы тестирования. Были рассмотрены также особенности тестирования рекламы в различных СМИ, для чего часто используются различные же подходы.
Особое внимание было уделено предварительному т стированию (претестированию), так как оно повышает вероятность подготовки наиболее эффективных текстов до того момента, как будут затрачены деньги на размещение рекламы.
Другой тип тестирования – посттестирование (или заключительное тестирование), со своей стороны, не имеет главного недостатка, присущего предварительному тестированию, – определенной доли искусственности. При заключительном тестировании поведение людей не искажается, оно естественно, реалистично. Во время заключительного тестирования учитывается ряд факторов, также серьезно влияющих на результаты. Прежде всего, это специфика средств распространения рекламы, время размещения рекламы, частота ее предъявления потребителям и т. д.
Если все рекламное сообщение, как правило, тестируют на способность стимулировать продажи, на убедительность, узнаваемость и запоминаемость продукта или марки, то рекламный текст обычно тестируют только на убедительность. В таких тестах внимание обращается в первую очередь на понимание заголовка, слогана, коды, ключевых слов.
Сегодня мы получаем новые инструменты для тестирования. Например, заголовки, ключевая слова можно успешно тестировать с помощью системы контекстной рекламы.
Каждый оценочный метод обладает специфическим сочетанием преимуществ и недостатков, а также разной стоимостью. Важным и очень простым, а главное, дешевым средством проверки эффективности рекламных текстов являются чек-листы (контрольные списки вопросов).
Видеоверсия лекции " Тестирование эффективности современной рекламы "
(готовится к публикации)
Более подробную информацию на эту тему можно найти в книге А. Назайкина
Ошибки, влекущие за собой снижение эффективности теста, появляются, если:
- Тест неправильно составлен
- Тест неправильно стандартизован
- Тест неправильно использован
Конструирование теста
Прежде всего, необходимо четко представлять себе то психологическое свойство, которое будет измерять будущий тест. Ни один тест не создается "с нуля", обычно за его созданием стоит длительная научная работа по изучению тематического материала.
Перед конструктором психологического теста стоит сложная задача - наиболее полно отразить все стороны измеряемого психологического свойства через минимальное количество заданий. Последнее условие - один из критериев эффективности теста. Это не означает, что личностный опросник Кеттела , содержащий полтысячи вопросов, можно считать неэффективным. При таком большом количестве измеряемых личностных факторов (16) такое количество вопросов является оптимальным. То же касается тестов на интеллект , мотивацию и другие обширные психические сферы. Остерегаться следует опросника, скажем, на стремление к риску , содержащего 250 вопросов.
Кроме этих требований, тест должен соответствовать целевой группе , на которую он направлен. Разрабатываются задания соответствующей сложности и доступности для разных возрастных групп, для людей с различными психическими нарушениями, для представителей разных национальных и языковых групп. Если тест предлагается к проведению в другой языковой группе или стране, его необходимо адаптировать.
К адаптации относятся не только перевод заданий, но и перестройка фраз, понятий, замена фразеологизмов, пословиц и поговорок на аналогичные им в данном языке. Смысл вопросов должен передаваться с учетом религиозных взглядов данной группы.
Также необходимо учитывать и некоторые эффекты, наблюдаемые при заполнении людьми тестовых заданий. Так называемый эффект социальной желательности срабатывает тогда, когда человек в своих ответах хочет представить себя в лучшем свете. Многие тесты вооружены до зубов "шкалами лжи ", вопросами-ловушками и пр. Но и это не всегда помогает - человек находит одинаковые вопросы, держит в памяти свои ответы.
Есть еще один прием - подмена цели теста в инструкции , если эта цель вообще открывается испытуемому. Тогда человек, отвечая на вопросы, показывает себя хорошо с одной стороны (ложная цель) и дает более или менее достоверные сведения о другой стороне (истинная цель), которая на самом деле измеряется данным тестом.
Существуют и требования к формулировке вопросов, к порядку их расстановки в тесте. Они опять же зависят от целевой группы, на которую тест рассчитан.
Правильно составленный тест еще нельзя назвать разработанным. Для этого он должен быть стандартизован.
Стандартизация
Стандартизация теста обеспечивает возможность сравнения полученных с его помощью данных от разных людей. Для этого необходимо, чтобы все эти люди находились в равных условиях. На психологическом языке это называется "контроль всех зависимых переменных". В идеале единственной независимой переменной в тесте будет личность испытуемого. Для обеспечения равных условий разработчик теста дает специальные указания по его проведению. Они включают:
- Специфику стимульного материала
- Временные ограничения (time limits)
- Инструкцию испытуемым
- Пробные образцы заданий
- Допустимые ответы на вопросы (если таковые ограничения необходимы)
Кроме этих указаний, в приложение к тесту включаются специально установленные нормы ответов (в "сырых баллах") и их интерпретации.
Помимо стандартизации тест должен быть проверен на предмет своей эффективности по критериям надежности и валидности. Очень часто эти понятия делают взаимозаменяемыми, поэтому рассмотрим, какое значение имеет каждое из них.
Надежность
Под надежностью понимают согласованность результатов, полученных при каждом повторном выполнении теста одним и тем же испытуемым, с результатами его первого тестирования. Абсолютной тестовой надежности не существует, погрешности допускаются, однако чем они выше, тем ниже тестовая эффективность. Надежность можно проверить следующими методами:
- тест-ретестовая надежность подразумевает многократное выполнение одного теста и корреляционное сравнение полученных результатов.
- разделенная надежность определяется при делении теста на две части и сравнение результатов выполнения двух частей по отдельности.
- эквивалентная надежность выявляется путем предъявления испытуемому теста и его альтернативного варианта. Полученные результаты также сравниваются между собой.
Валидность
Психологические словари раскрывают понятие валидности как степени соответствия теста своему назначению измерять то, для чего он создан; действительной способности теста измерять ту психологическую характеристику, для диагностики которой он заявлен. Количественно валидность теста может выражаться через корреляции результатов, полученных с его помощью, с другими показателями, например, с успешностью выполнения соответствующей деятельности.
Кроме того, валидность теста можно установить, сравнивая его результаты с результатами по аналогичным методикам. К примеру, разработанный тест на вербальный интеллект можно провести вместе с известным тестом Амтхауэра, сравнив затем их результаты. Высокая корреляция результатов будет означать высокую валидность - значит, новый тест действительно измеряет вербальный интеллект, а не речевые способности, память, внимание и т.д.
Выше было сказано про ошибки на этапе использования теста. Нарушение условий его проведения, рекомендуемых в приложениях, может привести к снижению валидности. Допустим, мы проводим тест на запоминание слов и, видя, что испытуемый достаточно способный, увеличиваем скорость прочтения списка слов. В этом случае увеличение скорости будет дополнительной независимой переменной, проще говоря, помехой. В результате вместо скорости запоминания мы будем измерять стрессоустойчивость личности.
Оценка валидности теста включает следующие этапы:
- определение очевидной валидности (face validity). Такую валидность видно, что говорится, "невооруженным глазом" - оценивается общее соответствие теста его назначению.
- определение концептуальной валидности (construct validity). Степень соответствия теста, измеряющего какое-либо свойство, общепринятым теоретическим представлениям об этом свойстве. Как правило, эта валидность оценивается экспертами.
- определение эмпирической валидности (empirical validity). Выбирается критерий (независимая переменная), с которой связываются результаты теста. К примеру, критерием для теста готовности к школе может стать общая оценка успеваемости первоклассника.
- определение содержательной валидности (content validity). Разработанный тест должен включать вопросы для оценки максимально возможного числа параметров того свойства, которое этот тест измеряет (выше упоминалось первое правило составления теста - максимальное количество параметров свойства через минимальное количество заданий). Эта валидность также оценивается с помощью экспертных оценок.
Кстати, не только новые тесты проходят такой экзамен. В настоящее время многие исследователи заняты анализом эффективности уже известных тестов. Недавняя полемика на страницах психологического журнала "Psychological Science in the Public Interest" поставила под сомнение эффективность таких "мэтров" психодиагностических инструментов, как тест чернильных пятен Роршаха, ТАТ (тест тематической апперцепции) и проективный тест-рисунок фигуры человека. Оказалось, что эти психодиагностические методики имеет низкую эмпирическую валидность, низкую тест-ретестовую надежность и некорректно составленные нормативные показатели.
Вышеприведенные методы оценки эффективности теста помогают психологу не только самому конструировать инструменты для измерения определенных свойств личности , но и выбирать из уже разработанных тестов наиболее качественные и надежные.
Психологический комплекс Effecton Studio
Основным приоритетом при создании комплекса Effecton Studio , было включение только научно-обоснованных и информативных методик. Кроме того, нашим пользователям, а также посетителям сайта и читателям рассылки, мы предоставляем информационное сопровождение психологических методик. Эффективности и эргономичности работы мы уделяем особое внимание - после прохождения психологических тестов Effecton Studio , пользователю не только сырые результаты, но и их интерпретация , предоставляются удобные методы группового тестирования и статистического анализа .
Разработано также множество других возможностей, с которыми мы рекомендуем Вам ознакомиться, скачав демонстрационную версию с нашего сайта и заказав комплекс для использования в своей организации. Вы можете также сообщить о комплексе другим заинтересованным пользователям, в случае чего, Вы получите 25% от стоимости сделки.
Ольга Данилова.
Эксклюзивный материал сайта "www.. Заимствование текста и/или связанных материалов возможно только при наличии прямой и хорошо различимой ссылки на оригинал. Все права защищены.