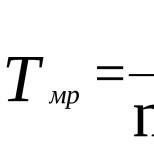Доверительный интервал для оценки среднего (дисперсия известна) в MS EXCEL
Доверительный интервал для математического ожидания - это такой вычисленный по данным интервал, который с известной вероятностью содержит математическое ожидание генеральной совокупности. Естественной оценкой для математического ожидания является среднее арифметическое её наблюденных значений. Поэтому далее в течение урока мы будем пользоваться терминами "среднее", "среднее значение". В задачах рассчёта доверительного интервала чаще всего требуется ответ типа "Доверительный интервал среднего числа [величина в конкретной задаче] находится от [меньшее значение] до [большее значение]". С помощью доверительного интервала можно оценивать не только средние значения, но и удельный вес того или иного признака генеральной совокупности. Средние значения, дисперсия, стандартное отклонение и погрешность, через которые мы будем приходить к новым определениям и формулам, разобраны на уроке Характеристики выборки и генеральной совокупности .
Точечная и интервальная оценки среднего значения
Если среднее значение генеральной совокупности оценивается числом (точкой), то за оценку неизвестной средней величины генеральной совокупности принимается конкретное среднее, которое рассчитано по выборке наблюдений. В таком случае значение среднего выборки - случайной величины - не совпадает со средним значением генеральной совокупности. Поэтому, указывая среднее значение выборки, одновременно нужно указывать и ошибку выборки. В качестве меры ошибки выборки используется стандартная ошибка , которая выражена в тех же единицах измерения, что и среднее. Поэтому часто используется следующая запись: .
Если оценку среднего требуется связать с определённой вероятностью, то интересующий параметр генеральной совокупности нужно оценивать не одним числом, а интервалом. Доверительным интервалом называют интервал, в котором с определённой вероятностью P находится значение оцениваемого показателя генеральной совокупности. Доверительный интервал, в котором с вероятностью P = 1 - α находится случайная величина , рассчитывается следующим образом:
![]() ,
,
α = 1 - P , которое можно найти в приложении к практически любой книге по статистике.
На практике среднее значение генеральной совокупности и дисперсия не известны, поэтому дисперсия генеральной совокупности заменяется дисперсией выборки , а среднее генеральной совокупности - средним значением выборки . Таким образом, доверительный интервал в большинстве случаев рассчитывается так:
![]() .
.
Формулу доверительного интервала можно использовать для оценки среднего генеральной совокупности, если
- известно стандартное отклонение генеральной совокупности;
- или стандартное отклонение генеральной совокупности не известно, но объём выборки - больше 30.
Среднее значение выборки
является несмещённой оценкой среднего генеральной совокупности .
В свою очередь, дисперсия выборки  не является несмещённой оценкой дисперсии генеральной совокупности .
Для получения несмещённой оценки дисперсии генеральной совокупности в формуле дисперсии выборки объём
выборки n
следует заменить на n
-1.
не является несмещённой оценкой дисперсии генеральной совокупности .
Для получения несмещённой оценки дисперсии генеральной совокупности в формуле дисперсии выборки объём
выборки n
следует заменить на n
-1.
Пример 1. Собрана информация из 100 случайно выбранных кафе в некотором городе о том, что среднее число работников в них составляет 10,5 со стандартным отклонением 4,6. Определить доверительный интервал 95% числа работников кафе.
где - критическое значение стандартного нормального распределения для уровня значимости α = 0,05 .
Таким образом, доверительный интервал 95% среднего числа работников кафе составил от 9,6 до 11,4.
Пример 2. Для случайной выборки из генеральной совокупности из 64 наблюдений вычислены следующие суммарные величины:
сумма значений в наблюдениях ,
сумма квадратов отклонения значений от среднего ![]() .
.
Вычислить доверительный интервал 95 % для математического ожидания.
вычислим стандартное отклонение:
 ,
,
вычислим среднее значение:
![]() .
.
Подставляем значения в выражение для доверительного интервала:
где - критическое значение стандартного нормального распределения для уровня значимости α = 0,05 .
Получаем:
Таким образом, доверительный интервал 95% для математического ожидания данной выборки составил от 7,484 до 11,266.
Пример 3. Для случайной выборки из генеральной совокупности из 100 наблюдений вычислено среднее значение 15,2 и стандартное отклонение 3,2. Вычислить доверительный интервал 95 % для математического ожидания, затем доверительный интервал 99 %. Если мощность выборки и её вариация остаются неизменными, а увеличивается доверительный коэффициент, то доверительный интервал сузится или расширится?
Подставляем данные значения в выражение для доверительного интервала:
где - критическое значение стандартного нормального распределения для уровня значимости α = 0,05 .
Получаем:
![]() .
.
Таким образом, доверительный интервал 95% для среднего данной выборки составил от 14,57 до 15,82.
Вновь подставляем данные значения в выражение для доверительного интервала:
где - критическое значение стандартного нормального распределения для уровня значимости α = 0,01 .
Получаем:
![]() .
.
Таким образом, доверительный интервал 99% для среднего данной выборки составил от 14,37 до 16,02.
Как видим, при увеличении доверительного коэффициента увеличивается также критическое значение стандартного нормального распределения, а, следовательно, начальная и конечная точки интервала расположены дальше от среднего, и, таким образом, доверительный интервал для математического ожидания увеличивается.
Точечная и интервальная оценки удельного веса
Удельный вес некоторого признака выборки можно интерпретировать как точечную оценку удельного веса p этого же признака в генеральной совокупности. Если же эту величину нужно связать с вероятностью, то следует рассчитать доверительный интервал удельного веса p признака в генеральной совокупности с вероятностью P = 1 - α :
 .
.
Пример 4. В некотором городе два кандидата A и B претендуют на пост мэра. Случайным образом были опрошены 200 жителей города, из которых 46% ответили, что будут голосовать за кандидата A , 26% - за кандидата B и 28% не знают, за кого будут голосовать. Определить доверительный интервал 95% для удельного веса жителей города, поддерживающих кандидата A .
Часто оценщику приходится анализировать рынок недвижимости того сегмента, в котором располагается объект оценки. Если рынок развит, проанализировать всю совокупность представленных объектов бывает сложно, поэтому для анализа используется выборка объектов. Не всегда эта выборка получается однородной, иногда требуется очистить ее от экстремумов - слишком высоких или слишком низких предложений рынка. Для этой цели применяется доверительный интервал . Цель данного исследования - провести сравнительный анализ двух способов расчета доверительного интервала и выбрать оптимальный вариант расчета при работе с разными выборками в системе estimatica.pro.
Доверительный интервал - вычисленный на основе выборки интервал значений признака, который с известной вероятностью содержит оцениваемый параметр генеральной совокупности.
Смысл вычисления доверительного интервала заключается в построении по данным выборки такого интервала, чтобы можно было утверждать с заданной вероятностью, что значение оцениваемого параметра находится в этом интервале. Другими словами, доверительный интервал с определенной вероятностью содержит неизвестное значение оцениваемой величины. Чем шире интервал, тем выше неточность.
Существуют разные методы определения доверительного интервала. В этой статье рассмотрим 2 способа:
- через медиану и среднеквадратическое отклонение;
- через критическое значение t-статистики (коэффициент Стьюдента).
Этапы сравнительного анализа разных способов расчета ДИ:
1. формируем выборку данных;
2. обрабатываем ее статистическими методами: рассчитываем среднее значение, медиану, дисперсию и т.д.;
3. рассчитываем доверительный интервал двумя способами;
4. анализируем очищенные выборки и полученные доверительные интервалы.
Этап 1. Выборка данных
Выборка сформирована с помощью системы estimatica.pro. В выборку вошло 91 предложение о продаже 1 комнатных квартир в 3-ем ценовом поясе с типом планировки «Хрущевка».
Таблица 1. Исходная выборка
|
Цена 1 кв.м., д.е. |
|
Рис.1. Исходная выборка

Этап 2. Обработка исходной выборки
Обработка выборки методами статистики требует вычисления следующих значений:
1. Среднее арифметическое значение

2. Медиана - число, характеризующее выборку: ровно половина элементов выборки больше медианы, другая половина меньше медианы
 (для выборки, имеющей нечетное число значений)
(для выборки, имеющей нечетное число значений)
3. Размах - разница между максимальным и минимальным значениями в выборке

4. Дисперсия - используется для более точного оценивания вариации данных

5. Среднеквадратическое отклонение по выборке (далее - СКО) - наиболее распространённый показатель рассеивания значений корректировок вокруг среднего арифметического значения.

6. Коэффициент вариации - отражает степень разбросанности значений корректировок

7. коэффициент осцилляции - отражает относительное колебание крайних значений цен в выборке вокруг средней

Таблица 2. Статистические показатели исходной выборки
Коэффициент вариации, который характеризует однородность данных, составляет 12,29%, однако коэффициент осцилляции слишком велик. Таким образом, мы можем утверждать, что исходная выборка не является однородной, поэтому перейдем к расчету доверительного интервала.
Этап 3. Расчёт доверительного интервала
Способ 1. Расчёт через медиану и среднеквадратическое отклонение.
Доверительный интервал определяется следующим образом: минимальное значение - из медианы вычитается СКО; максимальное значение - к медиане прибавляется СКО.

Таким образом, доверительный интервал (47179 д.е.; 60689 д.е.)
Рис. 2. Значения, попавшие в доверительный интервал 1.

Способ 2. Построение доверительного интервала через критическое значение t-статистики (коэффициент Стьюдента)
С.В. Грибовский в книге «Математические методы оценки стоимости имущества» описывает способ вычисления доверительного интервала через коэффициент Стьюдента. При расчете этим методом оценщик должен сам задать уровень значимости ∝, определяющий вероятность, с которой будет построен доверительный интервал. Обычно используются уровни значимости 0,1; 0,05 и 0,01. Им соответствуют доверительные вероятности 0,9; 0,95 и 0,99. При таком методе полагают истинные значения математического ожидания и дисперсии практически неизвестными (что почти всегда верно при решении практических задач оценки).
Формула доверительного интервала:

n - объем выборки;
Критическое значение t- статистики (распределения Стьюдента) с уровнем значимости ∝,числом степеней свободы n-1,которое определяется по специальным статистическим таблицам либо с помощью MS Excel ( →"Статистические"→ СТЬЮДРАСПОБР);
∝ - уровень значимости, принимаем ∝=0,01.

Рис. 2. Значения, попавшие в доверительный интервал 2.

Этап 4. Анализ разных способов расчета доверительного интервала
Два способа расчета доверительного интервала - через медиану и коэффициент Стьюдента - привели к разным значениям интервалов. Соответственно, получилось две различные очищенные выборки.
Таблица 3. Статистические показатели по трем выборкам.
|
Показатель |
Исходная выборка |
1 вариант |
2 вариант |
|
Среднее значение |
|||
|
Дисперсия |
|||
|
Коэф. вариации |
|||
|
Коэф. осциляции |
|||
|
Количество выбывших объектов, шт. |
|||
На основании выполненных расчетов можно сказать, что полученные разными методами значения доверительных интервалов пересекаются, поэтому можно использовать любой из способов расчета на усмотрение оценщика.
Однако мы считаем, что при работе в системе estimatica.pro целесообразно выбирать метод расчета доверительного интервала в зависимости от степени развитости рынка:
- если рынок неразвит, применять метод расчета через медиану и среднеквадратическое отклонение, так как количество выбывших объектов в этом случае невелико;
- если рынок развит, применять расчет через критическое значение t-статистики (коэффициент Стьюдента), так как есть возможность сформировать большую исходную выборку.
При подготовке статьи были использованы:
1. Грибовский С.В., Сивец С.А., Левыкина И.А. Математические методы оценки стоимости имущества. Москва, 2014 г.
2. Данные системы estimatica.pro
Доверительный интервал – предельные значения статистической величины, которая с заданной доверительной вероятностью γ будет находится в этом интервале при выборке большего объема. Обозначается как P(θ - ε . На практике выбирают доверительную вероятность γ из достаточно близких к единице значений γ = 0.9 , γ = 0.95 , γ = 0.99 .Назначение сервиса . С помощью этого сервиса определяются:
- доверительный интервал для генерального среднего, доверительный интервал для дисперсии;
- доверительный интервал для среднего квадратического отклонения, доверительный интервал для генеральной доли;
Пример №1
. В колхозе из общего стада в 1000 голов овец выборочной контрольной стрижке подверглись 100 овец. В результате был установлен средний настриг шерсти 4,2 кг на одну овцу. Определить с вероятностью 0,99 среднюю квадратическую ошибку выборки при определении среднего настрига шерсти на одну овцу и пределы, в которых заключена величина настрига, если дисперсия равна 2,5 . Выборка бесповторная.
Пример №2
. Из партии импортируемой продукции на посту Московской Северной таможни было взято в порядке случайной повторной выборки 20 проб продукта «А». В результате проверки установлена средняя влажность продукта «А» в выборке, которая оказалась равной 6 % при среднем квадратическом отклонении 1 %.
Определите с вероятностью 0,683 пределы средней влажности продукта во всей партии импортируемой продукции.
Пример №3
. Опрос 36 студентов показал, что среднее количество учебников, прочитанных ими за учебный год, оказалось равным 6. Считая, что количество учебников, прочитанных студентом за семестр, имеет нормальный закон распределения со средним квадратическим отклонением, равным 6, найти:
А) с надежностью 0,99 интервальную оценку для математического ожидания этой случайной величины;
Б) с какой вероятностью можно утверждать, что среднее количество учебников, прочитанных студентом за семестр, вычисленное по данной выборке, отклонится от математического ожидания по абсолютной величине не больше, чем на 2.
Классификация доверительных интервалов
По виду оцениваемого параметра:По типу выборки:
- Доверительный интервал для бесконечной выборки;
- Доверительный интервал для конечной выборки;
Расчет средней ошибки выборки при случайном отборе
Расхождение между значениями показателей, полученных по выборке, и соответствующими параметрами генеральной совокупности называется ошибкой репрезентативности .Обозначения основных параметров генеральной и выборочной совокупности.
| Формулы средней ошибки выборки | |||
| повторный отбор | бесповторный отбор | ||
| для средней | для доли | для средней | для доли |
Формулы расчета численности выборки при собственно-случайном способе отбора
Доверительный интервал
Доверительный интервал - термин, используемый в математической статистике при интервальной (в отличие от точечной) оценке статистических параметров, что предпочтительнее при небольшом объёме выборки. Доверительным называют интервал, который покрывает неизвестный параметр с заданной надёжностью.
Метод доверительных интервалов разработал американский статистик Ежи Нейман , исходя из идей английского статистика Рональда Фишера .
Определение
Доверительным интервалом параметра θ распределения случайной величины X с уровнем доверия 100p% , порождённым выборкой (x 1 ,…,x n), называется интервал с границами (x 1 ,…,x n) и (x 1 ,…,x n), которые являются реализациями случайных величин L (X 1 ,…,X n) и U (X 1 ,…,X n), таких, что
.Граничные точки доверительного интервала и называются доверительными пределами .
Интерпретация доверительного интервала, основанная на интуиции, будет следующей: если p велико (скажем, 0,95 или 0,99), то доверительный интервал почти наверняка содержит истинное значение θ .
Еще одно истолкование понятию доверительного интервала: его можно рассматривать как интервал значений параметра θ , совместимых с опытными данными и не противоречащих им.
Примеры
- Доверительный интервал для математического ожидания нормальной выборки ;
- Доверительный интервал для дисперсии нормальной выборки .
Байесовский доверительный интервал
В байесовской статистике существует схожее, но отличающееся в некоторых ключевых деталях определение доверительного интервала. Здесь оцениваемый параметр сам считается случайной величиной с некоторым заданным априорным распределением (в простейшем случае - равномерным), а выборка фиксирована (в классической статистике всё в точности наоборот). Байесовский -доверительным интервал - это интервал , покрывающий значение параметра с апостериорной вероятностью :
.Как правило, классический и байесовский доверительные интервалы различаются. В англоязычной литературе байесовский доверительный интервал принято называть термином credible interval , а классический - confidence interval .
Примечания
ИсточникиWikimedia Foundation . 2010 .
- Детки (фильм)
- Колонист
Смотреть что такое "Доверительный интервал" в других словарях:
Доверительный интервал - интервал, вычисленный по выборочным данным, который с заданной вероятностью (доверительной) накрывает неизвестное истинное значение оцениваемого параметра распределения. Источник: ГОСТ 20522 96: Грунты. Методы статистической обработки результатов … Словарь-справочник терминов нормативно-технической документации
доверительный интервал - для скалярного параметра генеральной совокупности – это отрезок, с большой вероятностью содержащий этот параметр. Эта фраза без дальнейших уточнений бессмысленна. Поскольку границы доверительного интервала оцениваются по выборке, естественна его… … Словарь социологической статистики
ДОВЕРИТЕЛЬНЫЙ ИНТЕРВАЛ - метод оценивания параметров, отличающийся от точечного оценивания. Пусть задана выборка x1, . . ., хn из распределения с плотностью вероятности f(x, α), и а*=а*(x1, . . ., хn) оценка α, g(a*, α) плотность вероятности оценки. Ищем… … Геологическая энциклопедия
ДОВЕРИТЕЛЬНЫЙ ИНТЕРВАЛ - (confidence interval) Интервал, в котором достоверность значения параметра по населению, полученного на основе выборочного обследования, имеет определенную степень вероятности, например 95%, что обусловлено самой выборкой (sample). Ширина… … Экономический словарь
доверительный интервал - – интервал, в котором находится истинное значение определяемой величины с заданной доверительной вероятностью. Общая химия: учебник / А. В. Жолнин … Химические термины
Доверительный интервал ДИ - Доверительный интервал, ДИ * давяральны інтэрвал, ДІ * confidence interval интервал значения признака, рассчитанный для к. л. параметра распределения (напр., среднего значения признака) по выборке и с определенной вероятностью (напр., 95% для 95% … Генетика. Энциклопедический словарь
ДОВЕРИТЕЛЬНЫЙ ИНТЕРВАЛ - понятие, возникающее при оценке параметра статистич. распределения интервалом значений. Д. и. для параметра q, соответствующий данному коэф. доверия Р, равен такому интервалу (q1, q2), что при любом распределении вероятности неравенства… … Физическая энциклопедия
доверительный интервал - — Тематики электросвязь, основные понятия EN confidence interval … Справочник технического переводчика
доверительный интервал - pasikliovimo intervalas statusas T sritis Standartizacija ir metrologija apibrėžtis Dydžio verčių intervalas, kuriame su pasirinktąja tikimybe yra matavimo rezultato vertė. atitikmenys: angl. confidence interval vok. Vertrauensbereich, m rus.… … Penkiakalbis aiškinamasis metrologijos terminų žodynas
доверительный интервал - pasikliovimo intervalas statusas T sritis chemija apibrėžtis Dydžio verčių intervalas, kuriame su pasirinktąja tikimybe yra matavimo rezultatų vertė. atitikmenys: angl. confidence interval rus. доверительная область; доверительный интервал … Chemijos terminų aiškinamasis žodynas
Оценка доверительных интервалов
Цели обучения
Статистика рассматривает следующие две основные задачи :
У нас есть некоторая оценка, построенная на выборочных данных, и мы хотим сделать некоторое вероятностное утверждение относительно того, где находится истинное значение оцениваемого параметра.
У нас есть конкретная гипотеза, которую необходимо проверить на основе выборочных данных.
В данной теме мы рассматриваем первую задачу. Введем также определение доверительного интервала.
Доверительный интервал - это интервал, который строится вокруг оценочного значения параметра и показывает, где находится истинное значение оцениваемого параметра с априори заданной вероятностью.
Изучив материал данной темы, Вы:
узнаете, что такое доверительный интервал оценки;
научитесь классифицировать статистические задачи;
освоите технику построения доверительных интервалов, как по статистическим формулам, так и с помощью программного инструментария;
научитесь определять необходимые размеры выборок для достижения определенных параметров точности статистических оценок.
Распределения выборочных характеристик
Т-распределение
Как обсуждали выше распределение случайной величины близко к стандартизованному нормальному распределению с параметрами 0 и 1. Поскольку нам не известна величина σ, мы заменяем ее на некоторую оценку s . Величина уже имеет другое распределение, а именно или Распределение Стьюдента , которое определяется параметром n -1 (число степеней свободы). Это распределение близко к нормальному распределению (чем больше n , тем распределения ближе).
На рис. 95  представлено распределение Стьюдента с 30 степенями свободы. Как видно, оно весьма близко к нормальному распределению.
представлено распределение Стьюдента с 30 степенями свободы. Как видно, оно весьма близко к нормальному распределению.
Аналогично функциям для работы с нормальным распределением НОРМРАСП
и НОРМОБР
имеются функции для работы с t-распределением - СТЬЮДРАСП (TDIST)
и СТЬЮДРАСПОБР (TINV)
. Пример использования этих функций можно посмотреть в файле СТЬЮДРАСП.XLS (шаблон
и решение
) и на рис. 96  .
.
Распределения других характеристик
Как мы уже знаем, для определения точности оценивания математического ожидания нам необходимо t-распределение. Для оценивания других параметров, например, дисперсии, требуются другие распределения. Два из них - это F-распределение и x 2 -распределение .
Доверительный интервал для среднего значения
Доверительный интервал - это интервал, который строится вокруг оценочного значения параметра и показывает, где находится истинное значение оцениваемого параметра с априори заданной вероятностью.
Построение доверительного интервала для среднего значения происходит следующим образом :
Пример
В ресторане быстрого обслуживания планируется расширить ассортимент новым видом сэндвича. Для того чтобы оценить спрос на него, менеджер случайным образом планирует выбрать 40 посетителей из тех, кто уже попробовал его и предложить им оценить их отношение к новому продукту в баллах от 1 до 10. Менеджер хочет оценить ожидаемое количество баллов, которое получит новый продукт и построить 95%-й доверительный интервал этой оценки. Как это осуществить? (см. файл СЭНДВИЧ1.XLS (шаблон и решение ).
Решение
Для решения данной задачи можно воспользоваться . Результаты представлены на рис. 97  .
.
Доверительный интервал для суммарного значения
Иногда по выборочным данным требуется оценить не математическое ожидание, а общую сумму значений. Например, в ситуации с аудитором интерес может представлять оценка не средней величины счета, а суммы всех счетов.
Пусть N
- общее количество элементов, n
- размер выборки, T 3
- сумма значений в выборке, T" - оценка для суммы по всей совокупности, тогда ![]() , а доверительный интервал вычисляется по формуле , где s - оценка стандартного отклонения для выборки, - оценка среднего для выборки.
, а доверительный интервал вычисляется по формуле , где s - оценка стандартного отклонения для выборки, - оценка среднего для выборки.
Пример
Допустим, некоторая налоговая служба хочет оценить размер суммарных налоговых возвратов для 10 000 налогоплательщиков. Налогоплательщик либо получает возврат, либо доплачивает налоги. Найдите 95%-й доверительный интервал для суммы возврата при условии, что размер выборки составляет 500 человек (см. файл СУММА ВОЗВРАТОВ.XLS (шаблон и решение ).
Решение
В StatPro
нет специальной процедуры для этого случая, однако можно заметить, что границы можно получить из границ для среднего исходя из вышеприведенных формул (рис. 98  ).
).
Доверительный интервал для пропорции
Пусть p - математическое ожидание доли клиентов, а р в
- оценка этой доли, полученная по выборке размера n. Можно показать, что для достаточно больших  распределение оценки будет близко к нормальному с математическим ожиданием p
и стандартным отклонением
распределение оценки будет близко к нормальному с математическим ожиданием p
и стандартным отклонением ![]() . Стандартная ошибка оценки в данном случае выражается как
. Стандартная ошибка оценки в данном случае выражается как  , а доверительный интервал как
, а доверительный интервал как  .
.
Пример
В ресторане быстрого обслуживания планируется расширить ассортимент новым видом сэндвича. Для того чтобы оценить спрос на него, менеджер случайным образом выбрал 40 посетителей из тех, кто уже попробовал его и предложил им оценить их отношение к новому продукту в баллах от 1 до 10. Менеджер хочет оценить ожидаемую долю клиентов, которые оценивают новый продукт не менее чем в 6 баллов (он ожидает, что именно эти клиенты и будут потребителями нового продукта).
Решение
Первоначально создаем новый столбец по признаку 1, если оценка клиента была больше 6 баллов и 0 иначе (см. файл СЭНДВИЧ2.XLS (шаблон и решение ).
Способ 1
Подсчитывая количество 1, оцениваем долю, а далее используем формулы.
Значение z кр берется из специальных таблиц нормального распределения (например, 1,96 для 95%-го доверительного интервала).
Используя данный подход и конкретные данные для построения 95%-го интервала, получим следующие результаты (рис. 99  ). Критическое значение параметра z кр
равно 1,96. Стандартная ошибка оценки - 0,077. Нижняя граница доверительного интервала - 0,475. Верхняя граница доверительного интервала - 0,775. Таким образом, менеджер вправе полагать с 95%-й долей уверенности, что процент клиентов, оценивших новый продукт на 6 баллов и выше, будет между 47,5 и 77,5.
). Критическое значение параметра z кр
равно 1,96. Стандартная ошибка оценки - 0,077. Нижняя граница доверительного интервала - 0,475. Верхняя граница доверительного интервала - 0,775. Таким образом, менеджер вправе полагать с 95%-й долей уверенности, что процент клиентов, оценивших новый продукт на 6 баллов и выше, будет между 47,5 и 77,5.
Способ 2
Данная задача допускает решение стандартными средствами StatPro . Для этого достаточно заметить, что доля в данном случае совпадает со средним значением столбца Тип . Далее применим StatPro/Statistical Inference/One-Sample Analysis для построения доверительного интервала среднего значения (оценки математического ожидания) для столбца Тип . Полученные в этом случае результат, будут весьма близок к результату 1-го способа (рис. 99).
Доверительный интервал для стандартного отклонения
В качестве оценки стандартного отклонения используется s (формула приведена в разделе 1). Функцией плотности распределения оценки s является функция хи-квадрат , которая, как и t-распределение, имеет n-1 степень свободы. Имеются специальные функции для работы с этим распределением ХИ2РАСП (CHIDIST) и ХИ2ОБР (CHIINV) .
Доверительный интервал в этом случае уже будет не симметричным. Условная схема границ представлена на рис. 100 .
Пример
Станок должен производить детали диаметром 10 см. Однако в силу различных обстоятельств происходят ошибки. Контролера по качеству волнуют два обстоятельства: во-первых, среднее значение должно равняться 10 см; во-вторых, даже в этом случае, если отклонения будут велики, то многие детали будут забракованы. Ежедневно он делает выборку из 50 деталей (см. файл КОНТРОЛЬ КАЧЕСТВА.XLS (шаблон и решение ). Какие выводы может дать такая выборка?
Решение
Построим 95%-й доверительные интервалы для среднего и для стандартного отклонения с помощью StatPro/Statistical Inference/ One-Sample Analysis
(рис. 101  ).
).
Далее, используя предположение о нормальном распределении диаметров, рассчитаем долю бракованных изделий, задавшись предельным отклонением 0,065. Используя возможности таблицы подстановки (случай двух параметров), построим зависимость доли брака от среднего значения и стандартного отклонения (рис. 102  ).
).
Доверительный интервал для разности двух средних значений
Это одно из наиболее важных применений статистических методов. Примеры ситуаций.
Менеджер магазина одежды хотел бы знать, на сколько больше или меньше тратит в магазине средняя женщина-покупатель, чем мужчина.
Две авиакомпании летают аналогичными маршрутами. Организация-потребитель хотела бы сравнить разницу между среднеожидаемыми временами задержек рейсов по обеим авиакомпаниям.
Компания рассылает купоны на отдельные виды товаров в одном городе и не рассылает в другом. Менеджеры хотят сравнить средние объемы покупок этих товаров в ближайшие два месяца.
Автомобильный дилер часто имеет дело на презентациях с замужними парами. Чтобы понять их персональную реакцию на презентацию, пары часто опрашивают отдельно. Менеджер хочет оценить разницу в рейтингах указываемых мужчинами и женщинами.
Случай независимых выборок
Разность средних значений будет иметь t-распределение с n 1 + n 2 - 2 степенями свободы. Доверительный интервал для μ 1 - μ 2 выражается соотношением:

Данная задача допускает решение не только по вышеприведенным формулам, но и стандартными средствами StatPro . Для этого достаточно применить
Доверительный интервал для разности между пропорциями
Пусть - математическое ожидание долей. Пусть - их выборочные оценки, построенные по выборкам размера n 1 и n 2 соответственно. Тогда является оценкой для разности . Следовательно, доверительный интервал этой разности выражается как:
Здесь z кр является значением, полученным из нормального распределения по специальным таблицам (например, 1,96 для 95%-й доверительного интервала).
Стандартная ошибка оценки выражается в данном случае соотношением:
 .
.
Пример
Магазин, готовясь к большой распродаже, предпринял следующие маркетинговые исследования. Были выбраны 300 лучших покупателей, которые в свою очередь были случайным образом поделены на две группы по 150 членов в каждой. Всем из отобранных покупателей были разосланы приглашения для участия в распродаже, но только для членов первой группы был приложен купон, дающий право на скидку 5%. В ходе распродажи покупки всех 300 отобранных покупателей фиксировались. Каким образом менеджер может интерпретировать полученные результаты и сделать заключение об эффективности предоставления купонов? (см. файл КУПОНЫ.XLS (шаблон и решение )).
Решение
Для нашего конкретного случая из 150 покупателей, получивших купон на скидку, 55 сделали покупку на распродаже, а среди 150, не получивших купон, покупку сделали только 35 (рис. 103  ). Тогда значения выборочных пропорций соответственно 0,3667 и 0,2333. А выборочная разность между ними равна соответственно 0,1333. Полагая доверительный интервал 95%-м, находим по таблице нормального распределения z кр
= 1,96. Вычисление стандартной ошибки выборочной разности равно 0,0524. Окончательно получаем, что нижняя граница 95%-го доверительного интервала равна 0,0307, а верхняя граница 0,2359 соответственно. Полученные результаты можно интерпретировать таким образом, что на каждых 100 покупателей, получивших купон со скидкой, можно ожидать от 3 до 23 новых покупателей. Однако надо иметь в виду, что этот вывод сам по себе еще не означает эффективности применения купонов (поскольку, предоставляя скидку, мы теряем в прибыли!). Продемонстрируем это на конкретных данных. Предположим, что средний размер покупки равен 400 руб., из которых 50 руб. есть прибыль магазина. Тогда ожидаемая прибыль на 100 покупателях, не получивших купон, равна:
). Тогда значения выборочных пропорций соответственно 0,3667 и 0,2333. А выборочная разность между ними равна соответственно 0,1333. Полагая доверительный интервал 95%-м, находим по таблице нормального распределения z кр
= 1,96. Вычисление стандартной ошибки выборочной разности равно 0,0524. Окончательно получаем, что нижняя граница 95%-го доверительного интервала равна 0,0307, а верхняя граница 0,2359 соответственно. Полученные результаты можно интерпретировать таким образом, что на каждых 100 покупателей, получивших купон со скидкой, можно ожидать от 3 до 23 новых покупателей. Однако надо иметь в виду, что этот вывод сам по себе еще не означает эффективности применения купонов (поскольку, предоставляя скидку, мы теряем в прибыли!). Продемонстрируем это на конкретных данных. Предположим, что средний размер покупки равен 400 руб., из которых 50 руб. есть прибыль магазина. Тогда ожидаемая прибыль на 100 покупателях, не получивших купон, равна:
50 0,2333 100 = 1166,50 руб.
Аналогичные вычисления для 100 покупателей получивших купон, дают:
30 0,3667 100 = 1100,10 руб.
Уменьшение средней прибыли до 30 объясняется тем, что, используя скидку, покупатели, получившие купон, в среднем будут делать покупку на 380 руб.
Таким образом, итоговый вывод говорит о неэффективности использования таких купонов в данной конкретной ситуации.
Замечание. Данная задача допускает решение стандартными средствами StatPro . Для этого достаточно свести данную задачу к задаче оценки разности двух средних способом, а далее применить StatPro/Statistical Inference/Two-Sample Analysis для построения доверительного интервала разности двух средних значений.
Управление длиной доверительного интервала
Длина доверительного интервала зависит от следующих условий :
непосредственно данных (стандартное отклонение);
уровня значимости;
размера выборки.
Размер выборки для оценки среднего значения
Сначала рассмотрим задачу в общем случае. Обозначим данное нам значение половины длины доверительного интервала за В
(рис. 104  ). Нам известно, что доверительный интервал для среднего значения некоторой случайной величины X
выражается как
). Нам известно, что доверительный интервал для среднего значения некоторой случайной величины X
выражается как ![]() , где
, где ![]() . Полагая:
. Полагая:
![]() и выражая n
, получим .
и выражая n
, получим .
К сожалению, точное значение дисперсии случайной величины X нам не известно. Кроме этого, нам неизвестно и значение t кр , так как оно зависит от n через количество степеней свободы. В данной ситуации мы можем поступить следующим образом. Вместо дисперсии s используем какую-либо оценку дисперсии, по каким-либо имеющимся реализациям исследуемой случайной величины. Вместо значения t кр используем значение z кр для нормального распределения. Это вполне допустимо, поскольку функции плотности распределений для нормального и t-распределения очень близки (за исключением случая малых n ). Таким образом, искомая формула принимает вид:
 .
.
Поскольку формула дает, вообще говоря, нецелочисленные результат, в качестве искомого размера выборки берется округление с избытком результата.
Пример
В ресторане быстрого обслуживания планируется расширить ассортимент новым видом сэндвича. Для того чтобы оценить спрос на него, менеджер случайным образом планирует выбрать некоторое количество посетителей из тех, кто уже попробовал его, и предложить им оценить их отношение к новому продукту в баллах от 1 до 10. Менеджер хочет оценить ожидаемое количество баллов, которое получит новый продукт и построить 95%-й доверительный интервал этой оценки. При этом он хочет, чтобы половина ширины доверительного интервала не превышала 0,3. Какое количество посетителей ему необходимо опросить?
выглядит следующим образом:

Здесь р оц - оценка доли p , а В есть заданная половина длины доверительного интервала. Завышенное значение для n можно получить, используя значение р оц = 0,5. В этом случае длина доверительного интервала не будет превосходить заданного значения В при любом истинном значении p .
Пример
Пусть менеджер из предыдущего примера планирует оценить долю клиентов, отдавших предпочтение новому виду продукции. Он хочет построить 90%-й доверительный интервал, половина длины которого не превосходила бы 0,05. Сколько клиентов должно войти в случайную выборку?
Решение
В нашем случае значение z кр
= 1,645. Поэтому искомое количество вычисляется как  .
.
Если бы менеджер имел основания полагать, что искомое значение p составляет, например, примерно 0,3, то, подставляя это значение в вышеприведенную формулу, мы получили бы меньшее значение величины случайной выборки, а именно 228.
Формула для определения размеров случайной выборки в случае разности между двумя средними значениями записывается как:
 .
.
Пример
Некоторая компьютерная компания имеет сервисный центр по обслуживанию клиентов. В последнее время увеличилось количество жалоб клиентов на плохое качество обслуживания. В сервисном центре в основном работают сотрудники двух типов: не имеющие большого опыта, но закончившие специальные подготовительные курсы, и имеющие большой практический опыт, но не закончившие специальных курсов. Компания хочет проанализировать нарекания клиентов за последние полгода и сравнить их средние количества, приходящиеся на каждую из двух групп сотрудников. Предполагается, что количества в выборках по обеим группам будут одинаковые. Какое количество сотрудников необходимо включить в выборку, чтобы получить 95%-й интервал с половиной длины не более 2?
Решение
Здесь σ оц есть оценка стандартного отклонения обеих случайных переменных в предположении, что они близки. Таким образом, в нашей задаче нам необходимо каким-то образом получить эту оценку. Это можно сделать, например, следующим образом. Просмотрев данные по нареканиям клиентов за последние полгода, менеджер может заметить, что на каждого сотрудника в основном приходится от 6 до 36 нареканий. Зная, что для нормального распределения практически все значения удалены от среднего значения не более чем на три стандартных отклонения, он может с определенным основанием полагать, что:
![]() , откуда σ оц
= 5.
, откуда σ оц
= 5.
Подставляя это значение в формулу, получаем  .
.
Формула для определения размера случайной выборки в случае оценки разности между долями имеет вид:

Пример
Некоторая компания имеет две фабрики по производству аналогичной продукции. Менеджер компании хочет сравнить доли бракованной продукции на обеих фабриках. По имеющейся информации процент брака на обеих фабриках составляет от 3 до 5%. Предполагается построить 99%-й доверительный интервал с половиной длины не более 0,005 (или 0,5%). Какое количество изделий необходимо отобрать с каждой фабрики?
Решение
Здесь р 1оц и р 2оц являются оценками двух неизвестных долей брака на 1-й и 2-й фабрике. Если положить р 1оц = р 2оц = 0,5, то мы получим завышенное значение для n . Но поскольку в нашем случае мы имеем некоторую априорную информацию об этих долях, то мы берем верхнюю оценку этих долей, а именно 0,05. Получаем
Когда делается оценка некоторых параметров совокупности по выборочным данным, полезно дать не только точечную оценку параметра, но и указать доверительный интервал, который показывает, где может находиться точное значение оцениваемого параметра.
В данной главе мы также познакомились с количественными соотношениями, позволяющими строить такие интервалы для различных параметров; узнали способы управления длиной доверительного интервала.
Отметим также, что задачу оценки размеров выборки (задача планирования эксперимента) можно решить, используя стандартные средства StatPro , а именно StatPro/Statistical Inference/Sample Size Selection .